СКОЛЬКО АРМАТУРЫ В 1 ТОННЕ 14
Сортовой прокат
Листовой прокат
Нержавеющая сталь
Метизы и метсырье
Цветные металлы
Теоретический пересчет тонны арматуры диаметром 14 мм в метры – это один из вариантов, самый неудобный на практике. Сколько метров в 1 тонне арматуры диаметром 14 мм. Арматура и арматурная сталь диаметром 14 мм, в данном случае тоже продается по тоннажу. Кстати, для этого еще нужно будет узнать, сколько весит 1 метр арматуры диаметром 14 мм. Выписка из таблицы арматурных сталей – перевод тонн в метры, для арматуры диаметром 14 мм.
Сколько арматуры в 1 тонне 14
В любом случае количество метров в тонне будет одинаковым. Возникает противоречие. Для мелких потребителей, частных лиц, строителей, индивидуальных мастеров и небольших строительных подрядчиков, отпуск арматуры по тоннам, напротив – представляет собой определенные неудобства. Однако, такая справочная таблица по арматурам, весу арматурной стали и количеству метров в тоне, есть «под рукой» далеко не всегда. Поэтому, мы приводим выписку из таблицы, по которой вы сразу сможете узнать, сколько метров арматуры диаметром 14 мм в 1 тонне. Для крупных торговых организаций и металлобаз – это удобно. С непривычки, без достаточного опыта, быстро «сообразить», перевести тонну арматуры диаметром 14 мм в метры, затруднительно.
Поэтому, мы приводим выписку из таблицы, по которой вы сразу сможете узнать, сколько метров арматуры диаметром 14 мм в 1 тонне. Для крупных торговых организаций и металлобаз – это удобно. С непривычки, без достаточного опыта, быстро «сообразить», перевести тонну арматуры диаметром 14 мм в метры, затруднительно.
Можно, конечно, вооружиться калькулятором и произвести расчеты по формуле. Не всем она и нужна. Производители металлических профилей и различных видов стального проката отпускают свою продукцию для продажи, измеряя ее в тоннах. В 1 тонне арматуры диаметром 14 мм – количество погонных метров арматурного прута = 826.45 метра. Метраж в тонне не зависит от того как порезана арматура 14 мм, мерно или немерно, отпускается в прутках или в бухте в виде мотков.
Дело в том, что все расчеты для строительства, технически, логичнее делать исходя из количества метров арматуры. Гораздо разумнее узнать, сколько метров в 1 тонне арматуры диаметром 14 мм, воспользовавшись справочными данными из таблицы, по арматурным сталям.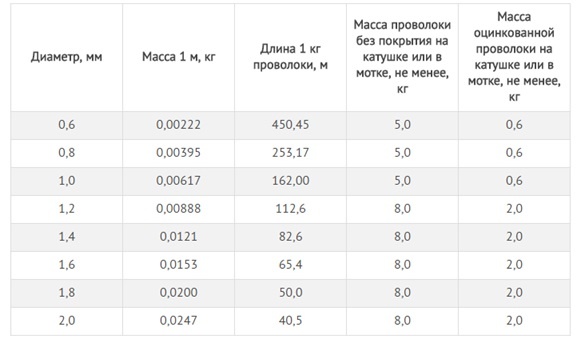 А действительно, сколько метров в 1 тонне арматуры 14 мм. Вы точно подсчитали, сколько метров арматуры диаметром 14 мм понадобится на вашем объекте, приезжаете на металлобазу, чтобы купить арматурную сталь и тут выясняется, что прейскурант или прайс на продажу арматуры диаметром 14 мм составлен в тоннах. Сколько арматуры в 1 тонне 14.
А действительно, сколько метров в 1 тонне арматуры 14 мм. Вы точно подсчитали, сколько метров арматуры диаметром 14 мм понадобится на вашем объекте, приезжаете на металлобазу, чтобы купить арматурную сталь и тут выясняется, что прейскурант или прайс на продажу арматуры диаметром 14 мм составлен в тоннах. Сколько арматуры в 1 тонне 14.
Смотрите также
СКОЛЬКО МЕТРОВ АРМАТУРЫ В ТОННЕ ДИАМЕТРОМ 8
Арматура А3 Ø 6 мм. О том, для чего нужно армирование при строительстве, читайте в статьях: Таблица теоретического веса строительной арматуры А3….
СКОЛЬКО ШТУК АРМАТУРЫ В ТОННЕ ДИАМЕТРОМ 10
В принципе это можно узнать и из таблицы веса арматуры. Диаметр Длина: Кол-во прутков: 10 1621м 135шт. № профиля арматуры или диаметр (мм)вес арматуры в…
АРМАТУРА 10 СКОЛЬКО МЕТРОВ В ТОННЕ
Чаще всего производство обеспечивает строительство арматурой А500Счетырех основных диаметров – 10 мм, 12 мм, 14 мм, 16 мм. При расчете, сколько штук…
1 ТОННА АРМАТУРЫ СКОЛЬКО МЕТРОВ
Так сколько метров арматуры в 1 тонне? Ответ на этот вопрос зависит, прежде всего, от материала, из которого она изготовлена (стеклопластик, сталь) и…
1 ТОННА АРМАТУРЫ 10 ММ СКОЛЬКО МЕТРОВ
Возникает проблема определения того, сколько штук арматуры в тонне, чтобы определить необходимое ее количество.
 Сколько в тонне содержится метров…
Сколько в тонне содержится метров…
 Сколько в тонне содержится метров…
Сколько в тонне содержится метров…Таблицы теоретического веса, приближенного к фактическому Масса металлопроката является приблизительной справочной величиной Предельные отклонения по массе +/- 5% Отпуск металлопроката со склада только в кг!
.
.
.
| ||||||


Сколько метров в тонне 14 арматуры
Калькулятор сколько метров арматуры в 1 тонне
Лестницы и перила. Козырьки и навесы. Люстры, бра, фонари.
Козырьки и навесы. Люстры, бра, фонари.
Кованая мебель. Каминные аксессуары. Кованые заборы. Решётки на окна. Металлические двери.
Подставки для цветов. Различные кованые изделия.
Количество метров и штук арматуры в 1 тонне зависит от диаметра используемого прута. Знать это необходимо при закупке материала, чтобы самостоятельно можно было проверить количество поставленного товара, а так же рассчитать объём арматуры для армирования монолитных конструкций. Разберем на примере, как производится подсчет, узнаем, сколько метров арматуры диаметром 12 мм в 1 тонне. Для расчета нам необходимо знать массу 1 метра, смотрим таблицу веса арматуры , он равен 0, кг. Теперь кг делим на 0, кг, получаем ,13 м.
Беседки и мостики. При расчете арматуры для фундамента ее количество считают в погонных метрах, то есть в результате расчета выясняется, сколько метров арматуры необходимо для армирования.
Производители металлических профилей и различных видов стального проката отпускают свою продукцию для продажи, измеряя ее в тоннах. Арматура и арматурная сталь диаметром 14 мм, в данном случае тоже продается по тоннажу. Для крупных торговых организаций и металлобаз — это удобно.
Мерой количества арматуры при продаже являются тонны, поэтому для определения стоимости нужного количества арматуры надо погонные метры перевести в тонны и смотреть цену за тонну. Сколько в тонне содержится метров арматуры зависит от ее диаметра: чем тоньше арматуры, тем больше метров в тонне. Для определения веса арматуры по ее длине, нужно знать ее диаметр. Арматура и арматурная сталь диаметром 14 мм, в данном случае тоже продается по тоннажу.
Для крупных торговых организаций и металлобаз — это удобно.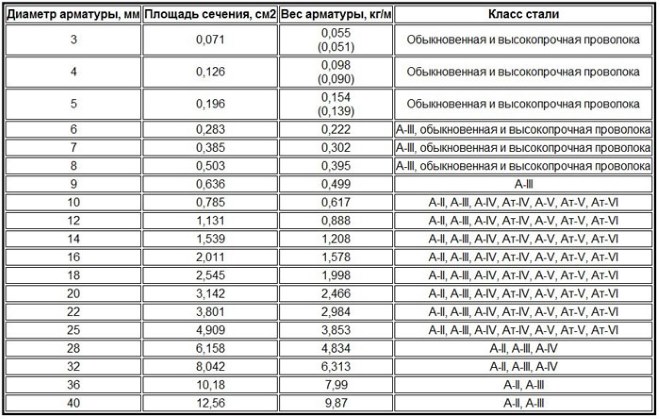 Для мелких потребителей, частных лиц, строителей, индивидуальных мастеров и небольших строительных подрядчиков, отпуск арматуры по тоннам, напротив — представляет собой определенные неудобства.
Для мелких потребителей, частных лиц, строителей, индивидуальных мастеров и небольших строительных подрядчиков, отпуск арматуры по тоннам, напротив — представляет собой определенные неудобства.
Далее Вы выбираете размер продукции.
Дело в том, что все расчеты для строительства, технически, логичнее делать исходя из количества метров арматуры. Возникает противоречие.
Вы точно подсчитали, сколько метров арматуры диаметром 14 мм понадобится на вашем объекте, приезжаете на металлобазу, чтобы купить арматурную сталь и тут выясняется, что прейскурант или прайс на продажу арматуры диаметром 14 мм составлен в тоннах. Можно, конечно, вооружиться калькулятором и произвести расчеты по формуле.
Теоретический пересчет тонны арматуры диаметром 14 мм в метры — это один из вариантов, самый неудобный на практике. Кстати, для этого еще нужно будет узнать, сколько весит 1 метр арматуры диаметром 14 мм.
Калькулятор веса арматуры. Вес метра арматуры. Количество метров арматуры в тонне.

Гораздо разумнее узнать, сколько метров в 1 тонне арматуры диаметром 14 мм, воспользовавшись справочными данными из таблицы, по арматурным сталям. Не всем она и нужна. Поэтому, мы приводим выписку из таблицы, по которой вы сразу сможете узнать, сколько метров арматуры диаметром 14 мм в 1 тонне.
Выписка из таблицы арматурных сталей — перевод тонн в метры, для арматуры диаметром 14 мм.
Метраж в тонне не зависит от того как порезана арматура 14 мм, мерно или немерно, отпускается в прутках или в бухте в виде мотков.
Арматура — Строительная компания «СЛОН»
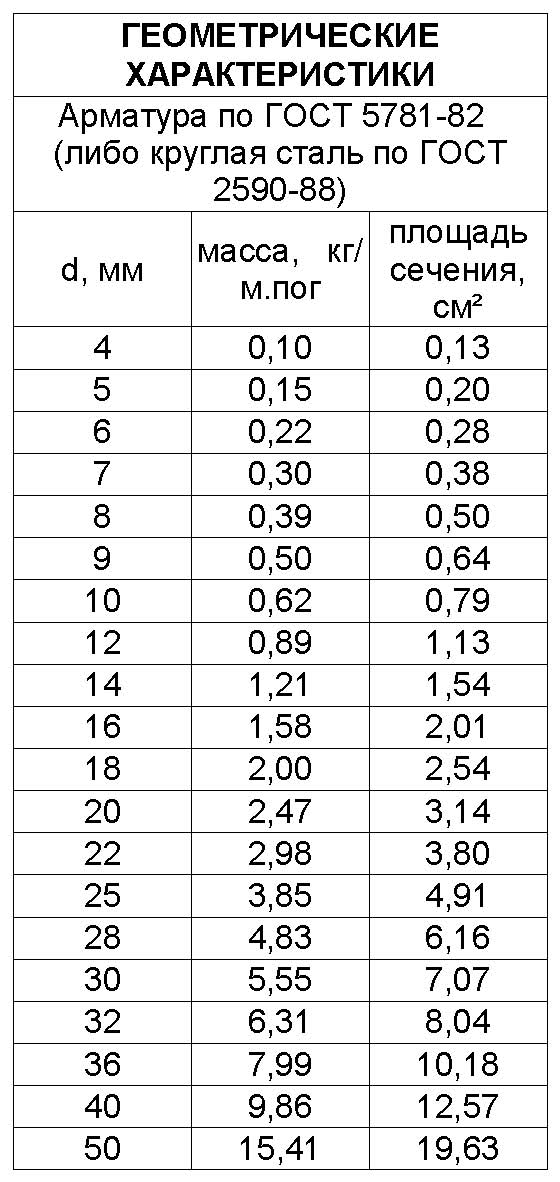
Таблица номер 1. Сколько весит 1 метр — арматура по ГОСТ 5781 — 53. Горячекатаная арматура. Примечание: Диаметр арматуры условно соответствует диаметру круглого стержня с таким же поперечным сечением.
|
Наименование металлопроката |
Минимальный диаметр d1 между рёбрами |
Максимальный диаметр d2 на ребре |
Расчётная пощадь сечения арматуры |
Вес погонного метра арматуры |
— |
— |
|
Сколько весит 1 метр — арматура 10 мм по ГОСТ 5781 — 53. |
9.3 |
11.3 |
0.78 |
0.62 |
— |
— |
|
Сколько весит 1 метр — арматура 12 мм по ГОСТ 5781 — 53. |
11 |
13.5 |
1.13 |
0.89 |
— |
— |
|
Сколько весит 1 метр — арматура 14 мм по ГОСТ 5781 — 53. |
13 |
15.5 |
1.54 |
1.21 |
— |
— |
|
Сколько весит 1 метр — арматура 16 мм по ГОСТ 5781 — 53. |
15 |
18 |
2.01 |
1.58 |
— |
— |
|
Сколько весит 1 метр — арматура 18 мм по ГОСТ 5781 — 53. |
17 |
20 |
2.54 |
2.00 |
— |
— |
|
Сколько весит 1 метр — арматура 20 мм по ГОСТ 5781 — 53. |
19 |
22 |
3.14 |
2.47 |
— |
— |
|
Сколько весит 1 метр — арматура 22 мм по ГОСТ 5781 — 53. |
21 |
24 |
3.80 |
2.98 |
— |
— |
|
Сколько весит 1 метр — арматура 25 мм по ГОСТ 5781 — 53. |
24 |
27 |
4.91 |
3.85 |
— |
— |
|
Сколько весит 1 метр — арматура 28 мм по ГОСТ 5781 — 53. |
26.5 |
30.5 |
6.16 |
4.83 |
— |
— |
|
Сколько весит 1 метр — арматура 32 мм по ГОСТ 5781 — 53. |
30.5 |
34.5 |
8.04 |
6.31 |
— |
— |
|
Сколько весит 1 метр — арматура 36 мм по ГОСТ 5781 — 53. |
34.5 |
39.5 |
10.18 |
7.99 |
— |
— |
|
Сколько весит 1 метр — арматура 40 мм по ГОСТ 5781 — 53. |
38.5 |
43.5 |
12.57 |
9.87 |
— |
— |
|
Сколько весит 1 метр — арматура 45 мм по ГОСТ 5781 — 53. |
43.0 |
49.0 |
15.90 |
12.48 |
— |
— |
|
Сколько весит 1 метр — арматура 50 мм по ГОСТ 5781 — 53. |
48.0 |
54.0 |
19.63 |
15.41 |
— |
— |
|
Сколько весит 1 метр — арматура 55 мм по ГОСТ 5781 — 53. |
53.0 |
59.0 |
23.76 |
18.65 |
— |
— |
|
Сколько весит 1 метр — арматура 60 мм по ГОСТ 5781 — 53. |
58.0 |
64.0 |
28.27 |
22.19 |
— |
— |
|
Сколько весит 1 метр — арматура 70 мм по ГОСТ 5781 — 53. |
68.0 |
74.0 |
38.48 |
30.21 |
— |
— |
|
Сколько весит 1 метр — арматура 80 мм по ГОСТ 5781 — 53. |
77.5 |
83.5 |
50.27 |
39.46 |
— |
— |
|
Сколько весит 1 метр — арматура 90 мм по ГОСТ 5781 — 53. |
87.5 |
93.5 |
50.27 |
39.46 |
— |
— |



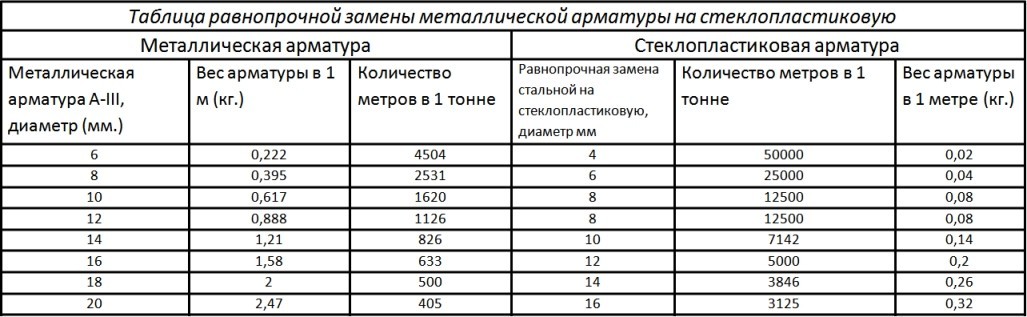

Таблица номер 2. Сколько весит 1 метр — арматура по ГОСТ 7314 — 55. Горячекатаная арматура из низколегированной стали марки 25ГС. Примечание: Диаметр арматуры условно соответствует диаметру круглого стержня с таким же поперечным сечением.
|
Наименование металлопроката |
Минимальный диаметр d1 между рёбрами |
Максимальный диаметр d2 на ребре |
Расчётная пощадь сечения арматуры |
Вес погонного метра арматуры |
— |
— |
|
колько весит 1 метр — арматура 6 мм по ГОСТ 7314 — 55. |
5.57 |
6.75 |
0.283 |
0.222 |
— |
— |
|
Сколько весит 1 метр — арматура 7 мм по ГОСТ 7314 — 55. |
6.75 |
7.75 |
0.385 |
0.302 |
— |
— |
|
Сколько весит 1 метр — арматура 8 мм по ГОСТ 7314 — 55. |
7.5 |
9.0 |
0.503 |
0.395 |
— |
— |
|
Сколько весит 1 метр — арматура 9 мм по ГОСТ 7314 — 55. |
8.5 |
10.0 |
0.636 |
0.50 |
— |
— |
|
Сколько весит 1 метр — арматура 10 мм по ГОСТ 7314 — 55. |
9.3 |
11.3 |
0.785 |
0.62 |
— |
— |
|
Сколько весит 1 метр — арматура 12 мм по ГОСТ 7314 — 55. |
11.0 |
13.5 |
1.13 |
0.89 |
— |
— |
|
Сколько весит 1 метр — арматура 14 мм по ГОСТ 7314 — 55. |
13.0 |
15.5 |
1.54 |
1.21 |
— |
— |
|
Сколько весит 1 метр — арматура 16 мм по ГОСТ 7314 — 55. |
15.0 |
18.0 |
2.01 |
1.58 |
— |
— |
|
Сколько весит 1 метр — арматура 18 мм по ГОСТ 7314 — 55. |
17.0 |
20.0 |
2.54 |
2.00 |
— |
— |
|
Сколько весит 1 метр — арматура 20 мм по ГОСТ 7314 — 55. |
19.0 |
22.0 |
3.14 |
2.47 |
— |
— |
|
Сколько весит 1 метр — арматура 22 мм по ГОСТ 7314 — 55. |
21.0 |
24.0 |
3.80 |
2.98 |
— |
— |
|
Сколько весит 1 метр — арматура 25 мм по ГОСТ 7314 — 55. |
24.0 |
27.0 |
4.91 |
3.85 |
— |
— |
|
Сколько весит 1 метр — арматура 28 мм по ГОСТ 7314 — 55. |
26.5 |
30.5 |
6.16 |
4.83 |
— |
— |
|
Сколько весит 1 метр — арматура 32 мм по ГОСТ 7314 — 55. |
30.5 |
34.5 |
8.04 |
6.31 |
— |
— |
|
Сколько весит 1 метр — арматура 36 мм по ГОСТ 7314 — 55. |
34.5 |
39.5 |
10.18 |
7.99 |
— |
— |
|
Сколько весит 1 метр — арматура 40 мм по ГОСТ 7314 — 55. |
38.5 |
43.5 |
12.57 |
9.87 |
— |
— |





|
Номер швеллера |
Размер, мм |
Вес, кг/м |
|||
|
h |
b |
s |
t |
||
|
5У |
50 |
32 |
4,4 |
7,0 |
4,84 |
|
6,5У |
65 |
36 |
4,4 |
7,2 |
5,90 |
|
8У |
80 |
40 |
4,5 |
7,4 |
7,05 |
|
10У |
100 |
46 |
4,5 |
7,6 |
8,59 |
|
12У |
120 |
52 |
4,8 |
7,8 |
10,40 |
|
14у |
140 |
58 |
4,9 |
8,1 |
12,30 |
|
16у |
160 |
64 |
5,0 |
8,4 |
14,20 |
|
18у |
180 |
70 |
5,1 |
8,7 |
16,30 |
|
18аУ |
180 |
74 |
5,1 |
9,3 |
17,40 |
|
20У |
200 |
76 |
5,2 |
9,0 |
18,40 |
|
20У |
220 |
82 |
5,4 |
9,5 |
21,00 |
|
24У |
240 |
90 |
5,6 |
10,0 |
24,00 |
|
30У |
300 |
100 |
6,5 |
11,0 |
31,80 |
|
33У |
330 |
105 |
7,0 |
11,7 |
36,50 |
|
36у |
360 |
110 |
7,5 |
12,6 |
41,90 |
|
40У |
400 |
115 |
8,0 |
13,5 |
48,30 |
|
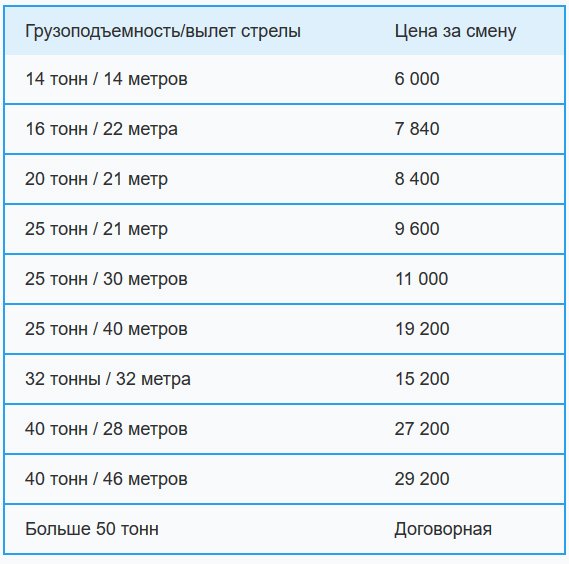
Вес погонного метра уголка ГОСТ 8509-83 |
|||
|
наименование |
размер, мм |
вес погонного метра, кг |
метров в тонне, м |
|
уголок |
25*25*3 |
1,12 |
892,86 |
|
уголок |
25*25*4 |
1,46 |
684,93 |
|
уголок |
32*32*3 |
1,46 |
684,93 |
|
уголок |
32*32*4 |
1,91 |
523,56 |
|
уголок |
35*35*3 |
1,60 |
625,00 |
|
уголок |
35*35*4 |
2,10 |
476,19 |
|
уголок |
40*40*4 |
2,42 |
413,22 |
|
уголок |
40*40*5 |
2,98 |
335,57 |
|
уголок |
45*45*4 |
2,73 |
366,30 |
|
уголок |
45*45*5 |
3,37 |
296,74 |
|
уголок |
50*50*4 |
3,05 |
327,87 |
|
уголок |
50*50* 5 |
3,77 |
265,25 |
|
уголок |
63*63*5 |
4,81 |
207,90 |
|
уголок |
63*63*6 |
5,72 |
174,83 |
|
уголок |
70*70*6 |
6,39 |
156,49 |
|
уголок |
70*70*7 |
7,39 |
135,32 |
|
уголок |
70*70*8 |
8,37 |
119,47 |
|
уголок |
75*75*5 |
5,80 |
172,41 |
|
уголок |
75*75*6 |
6,89 |
145,14 |
|
уголок |
75*75*7 |
7,96 |
125,63 |
|
уголок |
80*80*6 |
7,36 |
135,87 |
|
уголок |
80*80*7 |
8,51 |
117,51 |
|
уголок |
80*80*8 |
9,65 |
103,63 |
|
уголок |
90*90*6 |
8,33 |
120,05 |
|
уголок |
90*90*7 |
9,64 |
103,73 |
|
уголок |
90*90*8 |
10,93 |
91,49 |
|
уголок |
100*100*7 |
10,79 |
92,68 |
|
уголок |
100*100*8 |
12,25 |
81,63 |
|
уголок |
100*100*10 |
15,10 |
66,23 |
|
уголок |
100*100*12 |
17,90 |
55,87 |
|
уголок |
125*125*8 |
15,46 |
64,68 |
|
уголок |
125*125*9 |
17,30 |
57,80 |
|
уголок |
125*125*10 |
19,10 |
52,36 |
|
уголок |
125*125*12 |
22,68 |
44,09 |
|
уголок |
140*140*9 |
19,41 |
51,52 |
|
уголок |
140*140*10 |
21,45 |
46,62 |
|
уголок |
140*140*12 |
25,50 |
39,22 |
|
уголок |
160*160*10 |
24,67 |
40,54 |
|
уголок |
160*160*12 |
28,35 |
35,27 |
|
уголок |
160*160*16 |
38,52 |
25,96 |
|
уголок |
180*180*11 |
30,47 |
32,82 |
|
уголок |
180*180*12 |
33,12 |
30,19 |
|
уголок |
200*200*12 |
36,97 |
27,05 |
|
уголок |
200*200*16 |
48,65 |
20,55 |
Конвертер массы из 1 тонны (метрических единиц) в кубические метры
Категория : главное меню • конкретное меню • метрические тонны
Количество: 1 тонна (метрическая система) (т) массыРавно: Объем 0,42 кубических метра (м3)
Преобразование тонны (метрических единиц) в кубические метры в масштабе конкретных единиц.
TOGGLE: из кубических метров в метрические тонны и наоборот.
CONVERT: между другими конкретными измерительными приборами — полный список.
Калькулятор конвертации для вебмастеров .
Бетон
Этот состав общего назначения для бетона , также называемый бетонно-заполнитель (4: 1 — заполнитель песок / гравий: цемент — соотношение смеси с водой), основан на массовой плотности бетона 2400 кг / м3 — 150 фунт / фут3 после отверждения (округлено). Удельная масса на кубический сантиметр, бетон имеет плотность 2,41 г / см3. Главная страница конкретного калькулятора.
Формула смешивания бетона с прочностью 4: 1 использует объемные порции (например,грамм. 4 ведра заполнителя бетона на 1 ведро воды.) Чтобы бетон не получился слишком влажным, добавляйте воду постепенно по мере перемешивания. При ручном замешивании бетона; сначала смешайте порции сухого вещества и только потом добавляйте воду. Этот тип бетона обычно армируют металлической арматурой или сеткой.
Преобразование единиц измерения бетона между тоннами (метрическая система) (т) и кубических метров (м3) , но в обратном направлении из кубических метров в метрические тонны.
| результат преобразования для бетона: | |||||
| Из | Обозначение | Результат | До | Обозначение | |
| 1 тонна (метрическая) | т | = 0,42 | кубических метров | м3 | |
Этот онлайн-конвертер бетона из тонны в кубометр — удобный инструмент не только для сертифицированных или опытных профессионалов.
Первая единица: тонна (метрическая система) (т) используется для измерения массы.
Секунда: кубический метр (м3) — единица объема.
бетона на 0,42 м3 эквивалентно 1 чему?
Количество кубических метров 0,42 м3 конвертируется в 1 тонну, одну тонну (метрическая система). Это РАВНОЕ значение массы бетона, равное 1 тонне (метрическая система), но в альтернативных единицах объема кубических метров.
Это РАВНОЕ значение массы бетона, равное 1 тонне (метрическая система), но в альтернативных единицах объема кубических метров.
Как преобразовать 2 метрические тонны (т) бетона в кубические метры (м3)? Есть ли формула расчета?
Сначала разделите две переменные единиц измерения. Затем умножьте результат на 2 — например:
0.41553601694915 * 2 (или разделите на / 0,5)
ВОПРОС :
1 т бетона =? м3
ОТВЕТ :
1 т = 0,42 м3 бетона
Калькулятор для других приложений …
Благодаря вышеупомянутой услуге расчета двух блоков, этот преобразователь бетона оказался полезным также в качестве онлайн-инструмента для:
1. Практики обмена измеренными значениями метрических тонн и кубометров бетона (т против м3).
2. Коэффициенты преобразования конкретных количеств — между многочисленными парами единиц.
3. Работа с бетоном — насколько он тяжел — ценности и свойства.
Международные символы единиц для этих двух конкретных измерений:
Аббревиатура или префикс (abbr. Short brevis), обозначение единицы для тонны (метрическая система):
Short brevis), обозначение единицы для тонны (метрическая система):
t
Сокращение или префикс (abbr.) Brevis — краткое обозначение единицы кубического метра:
м3
Одна тонна (метрическая система) бетона, переведенная в кубический метр, равна 0.42 м3
Сколько кубометров бетона в 1 тонне (метрическая система)? Ответ: изменение единицы измерения бетона в 1 т (тонна (метрическая система)) = 0,42 м3 (кубический метр) в качестве эквивалентной меры для того же типа бетона.
В принципе, при выполнении любой задачи измерения профессиональные люди всегда гарантируют, и их успех зависит от того, получают ли они наиболее точные результаты преобразования везде и всегда. Не только когда это возможно, это всегда так. Часто наличие только хорошей идеи (или большего количества идей) может быть несовершенным или достаточно хорошим решением.Если существует точная известная мера в t — метрических тоннах для конкретного количества, то правило состоит в том, что тонна (метрическая) величина преобразуется в м3 — кубические метры или любую другую конкретную единицу абсолютно точно.
Объем бетона в 1 кубический метр конвертер единиц
Категория : главное меню • конкретное меню • Кубометры
Количество: 1 кубический метр (м3) объемаРавно: 2,41 Масса метрических тонн (т)
Перевод значения кубических метров в метрические тонны в шкале конкретных единиц.
TOGGLE: из метрических тонн в кубические метры и наоборот.
CONVERT: между другими конкретными измерительными приборами — полный список.
Калькулятор конвертации для вебмастеров .
Бетон
Этот состав общего назначения для бетона , также называемый бетонно-заполнитель (4: 1 — заполнитель песок / гравий: цемент — соотношение смеси с водой), основан на массовой плотности бетона 2400 кг / м3 — 150 фунт / фут3 после отверждения (округлено).Удельная масса на кубический сантиметр, бетон имеет плотность 2,41 г / см3. Главная страница конкретного калькулятора.
В формуле для смешивания бетона с прочностью 4: 1 используются объемные порции (например, 4 ведра заполнителя для бетона на 1 ведро воды). Чтобы не получить слишком влажный бетон, добавляйте воду постепенно по мере перемешивания. При ручном замешивании бетона; сначала смешайте порции сухого вещества и только потом добавляйте воду. Этот тип бетона обычно армируют металлической арматурой или сеткой.
Чтобы не получить слишком влажный бетон, добавляйте воду постепенно по мере перемешивания. При ручном замешивании бетона; сначала смешайте порции сухого вещества и только потом добавляйте воду. Этот тип бетона обычно армируют металлической арматурой или сеткой.
Преобразование единиц измерения бетона между кубических метров (м3) и Метрических тонн (т) , но в другом обратном направлении из метрических тонн в кубические метры.
| результат преобразования для бетона: | |||||
| От | Символ | Результат | До | Символ | |
| 1 кубический метр | м3 | = 2,41 | Метрические тонны | т | |
Этот онлайн-конвертер бетона из кубометра в тонну — удобный инструмент не только для сертифицированных или опытных профессионалов.
Первая единица: кубический метр (м3) используется для измерения объема.
Секунда: тонна (метрическая система) (т) — единица массы.
бетона на 2,41 т эквивалентно 1 чему?
Количество метрических тонн 2,41 т конвертируется в 1 м3, один кубический метр. Это РАВНОЕ значение объема бетона, равное 1 кубическому метру, но в альтернативной единице массы метрические тонны.
Как перевести 2 кубических метра (м3) бетона в метрические тонны (т)? Есть ли формула расчета?
Сначала разделите две переменные единиц измерения.Затем умножьте результат на 2 — например:
2,4065302626279 * 2 (или разделите на / 0,5)
ВОПРОС :
1 м3 бетона =? т
ОТВЕТ :
1 м3 = 2,41 т бетона
Калькулятор для других приложений …
С помощью вышеупомянутой услуги расчета с двумя единицами, которую он предоставляет, этот преобразователь бетона оказался полезным также в качестве онлайн-инструмента для:
1. тренировки кубических метров и метрических тонн бетона (м3 vs.ф) обмен значениями измерений.
тренировки кубических метров и метрических тонн бетона (м3 vs.ф) обмен значениями измерений.
2. Коэффициенты преобразования конкретных количеств — между многочисленными парами единиц.
3. Работа с бетоном — насколько он тяжел — ценности и свойства.
Международные символы единиц для этих двух конкретных измерений:
Аббревиатура или префикс (abbr. Short brevis), обозначение единицы измерения кубического метра:
м3
Аббревиатура или префикс (abbr.) Brevis — краткое обозначение единицы тонны (метрическая система):
t
Один кубический метр бетона в тоннах (метрических единицах) равен 2.41 т
Сколько метрических тонн бетона в 1 кубическом метре? Ответ: изменение единицы измерения бетона в 1 м3 (кубический метр) равно 2,41 т (тонна (метрическая система)) в качестве эквивалентной меры для того же типа бетона.
В принципе, при выполнении любой задачи измерения профессиональные люди всегда гарантируют, и их успех зависит от того, получают ли они наиболее точные результаты преобразования везде и всегда. Не только когда это возможно, это всегда так. Часто наличие только хорошей идеи (или большего количества идей) может быть несовершенным или достаточно хорошим решением.Если есть точная известная мера в м3 — кубических метрах для количества бетона, правило состоит в том, что количество кубических метров преобразуется в т — метрические тонны или любую другую конкретную единицу абсолютно точно.
Не только когда это возможно, это всегда так. Часто наличие только хорошей идеи (или большего количества идей) может быть несовершенным или достаточно хорошим решением.Если есть точная известная мера в м3 — кубических метрах для количества бетона, правило состоит в том, что количество кубических метров преобразуется в т — метрические тонны или любую другую конкретную единицу абсолютно точно.
Арматурный стержень № 4 — Арматурный стержень № 4
Harris Supply Solutions предлагает арматуру №4, которая изготовлена из прочного композитного материала углеродистой стали. Эта обычная высококачественная арматура широко применяется в жилищном и легком коммерческом строительстве. В частности, арматурная сталь №4 используется для мощения дорог и автомагистралей, а в определенных климатических условиях ее также можно использовать для изготовления каркасов бассейнов.Ему часто доверяют в качестве укрепляющего материала для плит, опор, колонн и стен. Эта марка арматуры 1/2 дюйма известна в метрической системе как «13 мм».
Физические характеристики Арматуры №4:
- Вес на единицу длины: 0,668 фунта на фут (0,996 кг на метр)
- Номинальный диаметр: 0,5 дюйма (12,7 мм)
- Номинальная площадь: 129 квадратных миллиметров (0,2 квадратных дюйма)
| Британский размер стержня | «Мягкий», метрический размер | Вес на единицу длины | Масса на единицу длины | Номинальный диаметр (U.S.) | Номинальный диаметр (метрическая система) | Номинальная площадь (США) | Номинальная площадь (метрическая система) |
|---|---|---|---|---|---|---|---|
| # 4 | # 13 | 0,668 фунта / фут | 0,996 кг / м | 0,500 = ½ дюйма | 12,7 мм | 0,2 дюйма 2 | 129 в 2 |
В Harris Supply Solutions мы постоянно стремимся к тому, чтобы наши предложения продукции отражали последние технологические разработки и тенденции строительной отрасли. Наше внимание уделяется обеспечению наших уважаемых клиентов надежными, прочными и высококачественными изделиями промышленного армирования, которые необходимы им для выполнения своих обещаний по качеству строительства.
Наше внимание уделяется обеспечению наших уважаемых клиентов надежными, прочными и высококачественными изделиями промышленного армирования, которые необходимы им для выполнения своих обещаний по качеству строительства.
Мы обслуживаем клиентов по всей стране через эффективный региональный центр поставок и обслуживания. Если вы хотите узнать, подходит ли тот или иной арматурный стержень для вашего применения, или запросите расценки, свяжитесь с нашим отделом продаж.
# 4 Часто задаваемые вопросы по арматуреQ.Какой размер арматуры №4?
A. ½ ”
В. Каков диаметр арматурного стержня №4?
A. 0,50 дюйма или 12,7 мм
В. Каков вес арматурного стержня №4?
A. 0,668 фунта на фут
В. Сколько стоит арматура №4?
A. Цена будет зависеть от спроса / предложения и местоположения на рынке. Для получения более подробной информации свяжитесь с нами.
Полезные ссылки
Harris Supply Solutions — оптовый дистрибьютор для клиентов, ищущих долгосрочные партнерские отношения.Котировки цен доступны только для владельцев текущих счетов.
Чтобы запросить консультацию, свяжитесь с нами сегодня.
Характеристики армированных стекловолокном пластиковых стержней в качестве армирующего материала для бетонных конструкций
Реферат
Растущее использование стержней из армированного волокном пластика (FRP) для армирования бетонных конструкций требует либо разработки нового кодекса проектирования, либо принятия существующего. для учета инженерных характеристик материалов из стеклопластика.В этой статье предлагаются некоторые модификации к используемой в настоящее время модели ACI для расчета прочности на изгиб, отклонения рабочей нагрузки и минимального армирования, необходимого для предотвращения разрыва растягивающей арматуры. Для проверки правильности предложенных модификаций были проведены две серии испытаний. Первая серия была использована для проверки обоснованности изменений, внесенных в модели изгиба и прогиба служебной нагрузки. Результаты испытаний первой серии были также проанализированы для разработки двух простых моделей для расчета отклонения рабочей нагрузки для балок, армированных стержнями из стеклопластика (GFRP).Вторая серия была использована для проверки точности модификации, предложенной в модели минимального армирования.
Первая серия была использована для проверки обоснованности изменений, внесенных в модели изгиба и прогиба служебной нагрузки. Результаты испытаний первой серии были также проанализированы для разработки двух простых моделей для расчета отклонения рабочей нагрузки для балок, армированных стержнями из стеклопластика (GFRP).Вторая серия была использована для проверки точности модификации, предложенной в модели минимального армирования.
Результаты испытаний первой серии показывают, что изгибная способность балок, армированных стержнями из стеклопластика, может быть точно предсказана с использованием окончательной теории проектирования. Они также показывают, что текущая модель ACI для расчета отклонения служебной нагрузки недооценивает фактическое отклонение этих балок. Две предложенные модели для прогнозирования отклонения служебной нагрузки точно оценили измеренное отклонение при служебной нагрузке, и более простая из двух моделей дает лучшие прогнозы, чем модели, доступные в литературе. Результаты испытаний второй серии показывают, что существует отличное соответствие между прогнозируемым и записанным поведением испытательных образцов, что свидетельствует о применимости предложенной модели для расчета требуемого минимального армирования для балок, армированных стержнями из стеклопластика.
Результаты испытаний второй серии показывают, что существует отличное соответствие между прогнозируемым и записанным поведением испытательных образцов, что свидетельствует о применимости предложенной модели для расчета требуемого минимального армирования для балок, армированных стержнями из стеклопластика.
Ключевые слова
A. Стекловолокно
Железобетонные конструкции
Рекомендуемые статьиЦитирующие статьи (0)
Полный текстCopyright © 1999 Elsevier Science Ltd. Все права защищены.
Рекомендуемые артикулы
Ссылки на статьи
Размеры европейского арматурного стержня / арматурного стержня и таблица
Размеры и таблица размеров европейского арматурного стержня / арматурного стержня | что такое арматура | Европейские размеры арматуры | Таблица размеров европейской арматуры
В этой статье мы приводим европейские метрические размеры стержней / размеры арматурных стержней и их диаметр, так как мы знаем, что в разных странах мира есть свои собственные градации, спецификации стали и записи измерений для арматурных стержней / арматурных стержней, мы кратко объясняем различные европейские метрические размеры арматурных стержней, их номинальный диаметр в дюймах и миллиметрах, их номинальная площадь в квадратных дюймах и квадратных миллиметрах и их масса на единицу длины в фунтах на фут и кг на метр.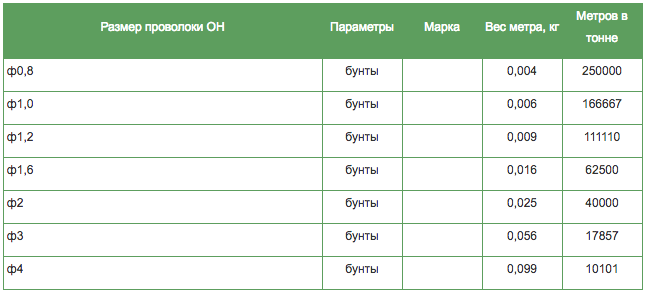 Это поможет зрителям лучше понять и легко выбрать наиболее подходящую арматуру в соответствии с требованиями.
Это поможет зрителям лучше понять и легко выбрать наиболее подходящую арматуру в соответствии с требованиями.
Арматура — это короткая форма арматурного стержня, это стальной стержень или стальная проволока, предусмотренная в качестве натяжного стержня, используемая в железобетонных конструкциях, таких как колонны, балки и плиты, в домостроении, а также в армированных каменных конструкциях. Применяется для повышения прочности бетонной конструкции.
Европейские метрические размеры арматурных стержней / арматурные стержни доступны в различных размерах, таких как 8,0 (метрический размер стержня 8 мм), 10,0 (считывается метрический размер стержня 10 мм), 12,0 (считывается метрический размер стержня 12 мм), 14 , 0 (читается как метрический размер стержня 14 мм), 16,0 (читается как метрический размер стержня 16 мм), 20,0 (считывается как метрический размер стержня 20 мм), 25,0 (читается как метрический размер стержня 25 мм), 32,0 (читать как метрический размер стержня 32 мм), 40,0 (читать как метрический размер стержня 40 мм) и 50,0 (читать как метрический размер стержня 50 мм). Он также будет настроен в соответствии с требованиями клиентов.
Он также будет настроен в соответствии с требованиями клиентов.
Европейские размеры арматуры: — Европейские метрические размеры арматурных стержней / арматурный стержень доступны в различных размерах, например 8,0 (считывается как метрический размер стержня 8 мм), 10,0 (считывается как метрический размер стержня 10 мм), 12,0 (считывается как метрический размер стержня 12 мм), 14,0 (читается как размер метрического стержня 14 мм), 16,0 (считывается как размер метрического стержня 16 мм), 20,0 (читается как размер метрического стержня 20 мм), 25,0 (считывается метрический стержень размер 25 мм), 32,0 (читается как размер метрического стержня 32 мм), 40,0 (читается как размер метрического стержня 40 мм) и 50,0 (читается как размер метрического стержня 50 мм).Он также будет настроен в соответствии с требованиями клиентов.
Таблица размеров европейской арматуры Европейский метрический размер арматуры 6,0 : — 6,0 арматурный стержень, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 6 мм, площадь поперечного сечения составляет 28,3 мм2, а их масса на единицу длины — в Килограмм на метр составляет 0,222 кг / м.
Физические характеристики европейской метрической арматуры размером 6,0
● метрический размер арматуры = 6,0
● номинальный диаметр в мм = 6 мм
● масса на единицу длины в килограммах на метр = 0.222 кг / м
● Площадь поперечного сечения = 28,3 мм2.
Европейский метрический размер арматуры 8,0: — 8,0 арматурный стержень, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 8 мм, площадь поперечного сечения составляет 50,30 мм2, а их масса на единицу длины — в миллиметрах. Килограмм на метр составляет 0,395 кг / м.
Физические характеристики европейской метрической арматуры размером 8,0
● метрический размер арматуры = 8,0
● номинальный диаметр в мм = 8 мм
● масса на единицу длины в килограммах на метр = 0.395 кг / м
● Площадь поперечного сечения = 50,30 мм2.
Европейский метрический размер арматуры 10,0: — 10,0 арматурный стержень, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 10 мм, площадь поперечного сечения составляет 78,5 мм2, а их масса на единицу длины — в миллиметрах. Килограмм на метр составляет 0,617 кг / м.
Килограмм на метр составляет 0,617 кг / м.
Физические характеристики европейской метрической арматуры размером 10,0
● метрический размер арматурного стержня = 10,0
● номинальный диаметр в мм = 10 мм
● масса на единицу длины в килограммах на метр = 0.617 кг / м
● Площадь поперечного сечения = 78,5 мм2.
Европейский метрический размер арматуры 12,0 : — Арматурный стержень 12,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 6 мм, площадь поперечного сечения составляет 113 мм2, а их масса на единицу длины в килограммах на метр составляет 0,888 кг / м.
Физические характеристики европейской метрической арматуры размером 12,0
● метрический размер арматуры = 12,0
● номинальный диаметр в мм = 12 мм
● масса на единицу длины в килограммах на метр = 0.888 кг / м
● Площадь поперечного сечения = 113 мм2.
Европейский метрический размер арматуры 14,0 : — Арматурный стержень 14,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 6 мм, площадь поперечного сечения составляет 154 мм2, а их масса на единицу длины в килограммах на метр составляет 1,21 кг / м.
Физические характеристики европейской метрической арматуры размером 14,0
● метрический размер арматуры = 14,0
● номинальный диаметр в мм = 14 мм
● масса на единицу длины в килограммах на метр = 1.21 кг / м
● Площадь поперечного сечения = 154 мм2.
Европейский метрический размер арматуры 16,0 : — Арматурный стержень 16,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 16 мм, площадь поперечного сечения составляет 201 мм2 и их масса на единицу длины в килограммах на метр составляет 1,579 кг / м.
Физические характеристики европейской метрической арматуры размером 16,0
● метрический размер арматуры = 16,0
● номинальный диаметр в мм = 16 мм
● масса на единицу длины в килограммах на метр = 1. 579 кг / м
579 кг / м
● Площадь поперечного сечения = 201 мм2.
Европейский метрический размер арматуры 20,0 : — Арматурный стержень 20,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 20 мм, площадь поперечного сечения составляет 314 мм2, а их масса на единицу длины в килограммах на метр составляет 2,467 кг / м.
Физические характеристики европейской метрической арматуры размером 20,0
● метрический размер арматуры = 20,0
● номинальный диаметр в мм = 20 мм
● масса на единицу длины в килограммах на метр = 2.467 кг / м
● Площадь поперечного сечения = 314 мм2.
Европейский метрический размер арматуры 25,0 : — Арматурный стержень 25,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 25 мм, площадь поперечного сечения составляет 491 мм2, а их масса на единицу длины в килограммах на метр составляет 3,855 кг / м.
Физические характеристики европейской метрической арматуры размером 25,0
● метрический размер арматуры = 25,0
● номинальный диаметр в мм = 25 мм
● масса на единицу длины в килограммах на метр = 3.855 кг / м
● Площадь поперечного сечения = 491 мм2.
Европейский метрический размер арматуры 28,0 : — Арматурный стержень 28,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 28 мм, площадь поперечного сечения составляет 616 мм2, а их масса на единицу длины в килограммах на метр составляет 4,83 кг / м.
Физические характеристики европейской метрической арматуры размером 28,0
● метрический размер арматуры = 28,0
● номинальный диаметр в мм = 28 мм
● масса на единицу длины в килограммах на метр = 4.83 кг / м
● Площадь поперечного сечения = 616 мм2.
Европейский метрический размер арматуры 32,0 : — Арматурный стержень 32,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 32 мм, площадь поперечного сечения составляет 804 мм2, а их масса на единицу длины в килограммах на метр составляет 6,316 кг / м.
Физические характеристики европейской метрической арматуры размером 32,0
● метрический размер арматуры = 32,0
● номинальный диаметр в мм = 32 мм
● масса на единицу длины в килограммах на метр = 6.316 / м
● Площадь поперечного сечения = 804 мм2.
Европейский метрический размер арматуры 40,0 : — Арматурный стержень 40,0, европейский арматурный стержень / арматурный стержень, их номинальный диаметр, измеренный в миллиметрах, равен 40 мм, площадь поперечного сечения составляет 1251 мм2, а их масса на единицу длины в килограммах на метр составляет 9,868 кг / м.
Физические характеристики европейской метрической арматуры размером 40,0
● метрический размер арматуры = 40,0
● номинальный диаметр в мм = 40 мм
● масса на единицу длины в килограммах на метр = 9.868 кг / м
● Площадь поперечного сечения = 1251 мм2.
Европейские метрические размеры арматурных стержней 50,0 : — 50,0 арматурных стержней, европейских арматурных стержней / арматурных стержней, их номинальный диаметр в миллиметрах, равный 50 мм, площадь поперечного сечения 1963 мм2 а их масса на единицу длины в килограммах на метр составляет 15,413 кг / м.
Физические характеристики европейской метрической арматуры размером 50,0
● метрический размер арматуры = 50,0
● номинальный диаметр в мм = 50 мм
● масса на единицу длины в килограммах на метр = 15.413 кг / м
● Площадь поперечного сечения = 1963 мм2.
Цены на бетон в 2021 году — Сколько стоит бетон?
Если вы заказываете бетон напрямую у поставщика готовой смеси, цены будут указаны в разбивке по дворам. Но если вы работаете с подрядчиком, их затраты будут указаны в квадратных футах.
Сколько стоит ярд бетона?
При оценке стоимости бетона используйте 125 долларов за ярд в качестве приблизительного значения. Однако цены на бетон различаются в зависимости от региона, и вам придется заплатить сбор за доставку готовой смеси, а также оплату труда при найме подрядчика.
Получите расценки у ближайших ко мне бетонных подрядчиков.
Стоимость бетона за квадратный фут
Ожидайте платить от до 4,25–6,25 долларов за квадратный фут за заливку простой бетонной плиты. Чтобы получить еще лучшее представление о том, сколько будет стоить ваш проект, запросите расценки у местных подрядчиков, которые могут прийти на сайт.
Чтобы получить еще лучшее представление о том, сколько будет стоить ваш проект, запросите расценки у местных подрядчиков, которые могут прийти на сайт.
Воспользуйтесь нашим калькулятором бетона, чтобы рассчитать, сколько ярдов вам понадобится для заливки перекрытий и фундаментов.
Ознакомьтесь с девятью основными этапами заливки бетона.
Бетонные подрядчики: Получите вакансии
Компоненты анализа конкретных цен:
Расчет цен на бетон — непростое занятие, так как на ценообразование на бетон влияет множество факторов. Некоторые из этих факторов включают следующее: профилирование, подготовка основания, бетонные формы и отделка, армирование и местная стоимость бетона.
Стоимость: 125 долларов за кубический ярд *
Бетон составляет большую часть стоимости конкретного проекта.Цены различаются в зависимости от региона, чтобы получить более точную оценку, обратитесь к местному поставщику готовой смеси. * Среднее значение по стране в 2020 г. (источник: NRMCA — Исследование отрасли производства готовых бетонных смесей)
(источник: NRMCA — Исследование отрасли производства готовых бетонных смесей)
Оценка: 50–70 долларов в час
Стоимость будет варьироваться в зависимости от количества земли, которое вам нужно переместить. Для трактора и оператора действуют почасовые ставки.
Суббаза: 12 — 18 долларов за кубический ярд
Стоимость доставки гравия или песка на строительную площадку.
О грунтовых основаниях и основаниях читайте здесь.
Бетонные формы и отделка: 1,50–2,00 доллара за квадратный фут
Самая большая стоимость труда — это бетонные формы. Устройство бетонных форм и отделка бетона — это кропотливая работа.
Подробнее о принадлежностях для формовки бетона.
Армирование: 0,15 — 0,30 доллара за квадратный фут
Армирование требуется, потому что все бетонные трещины, поэтому, если вы хотите, чтобы ваши трещины оставались небольшими, вам понадобится армирование. Проволочная сетка, арматура, пластиковая сетка и волокно в смеси — все это обычно используемые материалы.
Какая у меня цена на бетон?
Вы можете приблизительно оценить свой проект, используя приведенные выше цифры. Помните, что эта смета предназначена для «простого» бетона. Декоративные варианты, такие как штамповка (см. Стоимость штампованного бетона), окрашивание (см. Стоимость окрашенного бетона) и специальная отделка, значительно увеличат стоимость проекта.
Для простого бетона вы можете ожидать, что ваша цена упадет где-то между 4,25 и 6,25 долларов за квадратный фут в зависимости от размера и сложности проекта.
Стоимость декоративного бетона
Декоративный бетон — хороший вариант для домовладельцев, которым нужен элитный вид без высокой цены. Бетон — универсальный материал, который можно использовать для полов, столешниц, террас, подъездных дорожек и многого другого. Такие методы, как штамповка, окрашивание и полировка, могут превратить бетон, чтобы он выглядел как каменная плита, мрамор или другие дорогие материалы за небольшую часть стоимости.
Стоимость наружного бетона:
Стоимость внутреннего бетона:
По сравнению со стоимостью других материалов декоративный бетон — вариант средней ценовой категории.На открытом воздухе асфальт, обычный бетон и гравий более доступны, а натуральный камень и брусчатка — дороже. Внутри помещения ламинат и керамическая плитка будут стоить дешевле, а гранит, мрамор и древесина твердых пород — дороже. Декоративный бетон — это здорово, если вы можете позволить себе потратить дополнительные деньги, но не хотите разориться.
При определении стоимости проекта декоративного бетона, материалы и рабочая сила являются двумя основными факторами. Типичные используемые материалы: бетонная смесь, формовочные материалы, текстурирующие и окрашивающие продукты, герметики и т. Д.Трудозатраты будут варьироваться в зависимости от вашего проекта — его размера, нового или существующего бетона, степени детализации декоративных работ и многого другого. Получите предложения от нескольких подрядчиков, чтобы убедиться, что вы заключаете честную сделку.
Этот декоративный дворик из бетона выглядит как шифер, но стоит вдвое дешевле. Salzano Custom Concrete, Centerville, VA
Факторы, влияющие на стоимость декоративного бетона:
- Количество использованных цветов
- Количество используемых текстур тиснения
- Деталь конструкции (т.е. сложные выкройки дорогие)
- Особые детали, такие как вставки (часто встречаются в столешницах)
- Специальная форма или работа с пресс-формами (т.е. кривые и уникальные формы стоят дороже)
- Уровень полировки
Наконечник
Поинтересуйтесь у профессионала, он часто может выполнить проект по цене или ниже вашей стоимости из-за экономии на масштабе и доступа к надлежащему оборудованию. Найдите здесь местных подрядчиков по бетону, чтобы запросить ценовое предложение.
История цен:
Вот запись об изменении цен на бетон.Данные являются средними по стране от NRMCA.
- 2020: 125 долларов за ярд
- 2019: 121 доллар за ярд
- 2018: 113 долларов за ярд
- 2016: 108 долларов за ярд
- 2014: 98 долларов за ярд
- 2013: 93 доллара за ярд
- 2008 г .: 75 долларов за ярд
Последнее примечание:
Рассматривая цену, подумайте прежде всего о том, чтобы получить желаемое качество и обслуживание. Правильно сделанный бетон прослужит долгие годы, поэтому экономия одного-двух долларов на квадратный фут не будет экономией денег в долгосрочной перспективе, если работа будет выполнена неправильно.
Дополнительная информация:
Вернуться к заказу Бетон
Глубокое обучение с подкреплением пока не работает
24 июня 2018 г. примечание: если вы хотите привести пример из сообщения, пожалуйста процитируйте статью, из которой взят этот пример. Если вы хотите процитировать пост в целом можно использовать следующий BibTeX:
@misc {rlblogpost,
title = {Глубокое обучение с подкреплением пока не работает},
автор = {Ирпан, Алекс},
howpublished = {\ url {https: // www.alexirpan.com/2018/02/14/rl-hard.html}},
год = {2018}
}
В основном цитируются статьи из Berkeley, Google Brain, DeepMind и OpenAI. за последние несколько лет, потому что эта работа наиболее видна мне. Мне почти наверняка не хватает чего-то из старой литературы и других учреждения, и за это я прошу прощения — в конце концов, я всего лишь один парень.
Однажды в Facebook я сделал следующее заявление.
Когда кто-то спрашивает меня, может ли обучение с подкреплением решить их проблему, я отвечаю, что нет.Я думаю, что это верно как минимум в 70% случаев.
Глубокое обучение с подкреплением окружено горами ажиотажа. А также по уважительным причинам! Обучение с подкреплением — это невероятно общая парадигма, и, в принципе, надежная и производительная система RL должна отлично справляться с все. Объединение этой парадигмы с эмпирической силой глубокого обучения очевидное соответствие. Глубокий RL — одна из самых близких вещей, которая выглядит как AGI, и это та мечта, которая питает миллиарды долларов финансирования.
К сожалению, пока не работает.
Теперь я считаю, что может работать. Если бы я не верил в обучение с подкреплением, Я бы не стал над этим работать. Но на этом пути много проблем, многие из которых кажутся фундаментальными. трудный. Прекрасные демонстрации ученых агентов скрывают всю кровь, пот и слезы, которые идут на их создание.
Я уже несколько раз видел, как людей привлекала недавняя работа. Они пытались впервые глубокое обучение с подкреплением, и в обязательном порядке они недооценивать трудности глубокого RL.В любом случае «игрушечная проблема» не так проста, как кажется. И в обязательном порядке поле несколько раз их уничтожает, пока они не научатся устанавливать реалистичные ожидания исследований.
Это не вина кого-то конкретно. Это скорее системная проблема. Легко написать историю о положительном результате. Трудно делать то же самое для отрицательных. Проблема в том, что отрицательные — это те, которые исследователи встречаются чаще всего. В некотором смысле отрицательные случаи на самом деле важнее положительных моментов.
В оставшейся части поста я объясню, почему глубокий RL не работает, случаи, когда он действительно работает, и я вижу, что в будущем он будет работать более надежно. Я делаю это не потому, что хочу, чтобы люди перестали работать над глубоким RL. Я делаю это, потому что считаю, что решать проблемы легче, если есть согласие относительно того, в чем заключаются эти проблемы, и легче построить согласие, если люди действительно говорят о проблемах, а не независимо повторное обнаружение одних и тех же проблем снова и снова.
Я хочу увидеть более глубокое исследование RL. Я хочу, чтобы к этой сфере присоединились новые люди. я также хотят, чтобы новые люди знали, во что они ввязываются.
Прежде чем перейти к остальной части сообщения, несколько замечаний.
Я цитирую несколько статей в этом посте. Обычно я цитирую статью за ее убедительные отрицательные примеры, исключая положительные. Это не значит, мне не нравится газета. Мне нравятся эти газеты — их стоит прочитать, если у тебя есть время.
Я использую «обучение с подкреплением» и «глубокое обучение с подкреплением». взаимозаменяемо, потому что в моей повседневной жизни «RL» всегда неявно означает глубокий RL. Я критикую эмпирическое поведение глубокого подкрепления. обучение, а не обучение с подкреплением в целом. Статьи, которые я цитирую, обычно представляют агента с глубокой нейронной сетью. Хотя эмпирическая критика может относиться к линейному или табличному RL, я не уверенно они обобщают на более мелкие проблемы.Шумиха вокруг глубокого RL вызвана обещанием применить RL к большим, сложным, многомерные среды, в которых необходима хорошая аппроксимация функций. В частности, необходимо бороться с этой шумихой.
Структура этого сообщения — от пессимистичного к оптимистическому. Я знаю, что это немного долго, но я был бы признателен, если бы вы нашли время, чтобы прочтите весь пост перед тем, как ответить.
Без лишних слов, вот некоторые из случаев отказа глубокого RL.
Самым известным тестом для глубокого обучения с подкреплением является Atari. Как показано в теперь известной статье Deep Q-Networks, если вы объедините Q-Learning с нейронные сети разумного размера и некоторые приемы оптимизации, вы можете добиться человеческие или сверхчеловеческие возможности в нескольких играх Atari.
игр для Atari работают со скоростью 60 кадров в секунду. С в верхней части головы, можете ли вы оценить, сколько кадров в современном DQN необходимо достичь производительности человека?
Ответ зависит от игры, поэтому давайте взглянем на недавний Deepmind бумага, Rainbow DQN (Hessel et al, 2017).В этой статье проводится исследование абляции нескольких дополнительных достижений в области оригинальная архитектура DQN, демонстрирующая, что сочетание всех достижений дает лучшая производительность. Он превосходит человеческий уровень производительности более чем 40 из 57 Atari. попытки игр. Результаты отображаются на этой удобной диаграмме.
По оси ординат отложен средний балл, нормализованный для человека. Это вычисляется путем обучения 57 DQN, по одному для каждой игры Atari, нормализующие счет каждого агента таким образом, чтобы производительность человека составляет 100%, а затем нанесение медианного значения производительности по 57 игр.RainbowDQN преодолевает 100% порог примерно на уровне 18 миллионов кадров. Это соответствует примерно 83 часам игрового процесса, плюс сколько времени это займет обучить модель. Много времени для игры Atari, которую подбирает большинство людей. в течение нескольких минут.
Имейте в виду, 18 миллионов кадров — это действительно неплохо, если учесть, что предыдущая запись (Распределительный DQN (Bellemare et al, 2017)) потребовалось 70 миллионов кадров для достижения 100% медианной производительности, что примерно в 4 раза больше время.Что касается Nature DQN (Mnih et al, 2015), он никогда не достигает 100% медианной производительности даже после 200 миллионов кадров опыт.
Ошибка планирования гласит, что завершение чего-либо обычно занимает больше времени, чем вы думаете, что так и будет. Армирование у обучения есть своя собственная ошибка планирования — изучение политики обычно требует большего образцы, чем вы думаете.
Это проблема не только для Atari. Второй по популярности тест — это Тесты MuJoCo, набор задач, поставленных в физике MuJoCo симулятор.7 \) шагов для обучения, в зависимости от по задаче. Это поразительно большой опыт, чтобы управлять такой простой средой.
Статья о паркуре DeepMind (Heess et al, 2017), показано ниже, обученные политики, используя 64 сотрудника на протяжении более 100 часов. В документе не уточняется, что такое «рабочий» означает, но я предполагаю, что это означает 1 процессор.
Эти результаты: супер круто . Когда он впервые вышел, я был удивлен deep RL даже смог научиться этим беговым походкам.
В то же время тот факт, что для этого потребовалось 6400 часов ЦП, немного разочаровывает. Не то чтобы я ожидал, что на это потребуется меньше времени … досадно, что глубокий RL по-прежнему на порядки выше практического уровень эффективности выборки.
Здесь есть очевидный контрапункт: что, если мы просто проигнорируем эффективность выборки? Есть несколько настроек, в которых легко получить опыт. Игры большой пример. Но для любых настроек, где не соответствует действительности , RL сталкивается с подъемом. Battle, и, к сожалению, под эту категорию попадают большинство реальных настроек.
При поиске решения любой исследовательской задачи обычно компромиссы между разными целями. Вы можете оптимизировать для получения действительно хорошее решение для этой исследовательской проблемы, или вы можете оптимизировать для создания хорошего исследовательский вклад. Лучшие проблемы — это те, для которых нужно найти хорошее решение требует внесения хороших исследовательских вкладов, но может быть трудно найти доступные проблемы, соответствующие этим критериям.
Для получения исключительно хорошей производительности опыт работы с глубоким RL недостаточен. это здорово, потому что его постоянно побивают другими методами.Вот видео роботов MuJoCo, управляемых по онлайн-траектории. оптимизация. Правильные действия вычисляются почти в реальном времени, онлайн, с нет офлайн-обучения. Да, и он работает на оборудовании 2012 года. (Тасса и др., IROS 2012).
Я думаю, что это поведение хорошо сравнивается с паркуром. бумага. Чем отличается эта бумага от этой?
Разница в том, что Tassa et al используют прогнозирующий контроль модели, который позволяет выполнять планирование на основе реальной модели мира (симулятор физики).Безмодельный RL не выполняет этого планирования, и поэтому имеет гораздо более сложный работа. С другой стороны, если планирование на основе модели так сильно помогает, почему возиться с наворотами в обучении политике RL?
Аналогичным образом, вы можете легко превзойти DQN в Atari с помощью готовых Поиск по дереву Монте-Карло. Вот базовый уровень цифры из Guo et al, NIPS 2014. Они сравнивают оценки обученного DQN с оценками агента UCT. (где UCT — это стандартная версия MCTS, используемая сегодня.)
Опять же, это несправедливое сравнение, потому что DQN не выполняет поиск, а MCTS получает выполнять поиск по базовой модели (эмулятор Atari). Однако иногда вам наплевать на честные сравнения. Иногда ты просто хочу, чтобы вещь работала. (Если вас интересует полная оценка UCT, см. приложение к оригиналу Документ Arcade Learning Environment (Bellemare et al, JAIR 2013).
Обучение с подкреплением теоретически может работать для чего угодно, включая среды, в которых модель мира неизвестна.Однако эта общность приходится расплачиваться: трудно использовать информацию, касающуюся конкретной проблемы, которая может помочь в обучении, что заставляет вас использовать тонны образцов для изучения вещи, которые можно было жестко запрограммировать.
Практическое правило заключается в том, что, за исключением редких случаев, алгоритмы, специфичные для конкретной области работают быстрее и лучше, чем обучение с подкреплением. Это не проблема, если вы делаете глубокий RL ради глубокого RL, но я лично меня расстраивает, когда я сравниваю производительность RL с, ну, что-нибудь еще.Одна из причин, по которой мне так понравился AlphaGo, — это , потому что это был однозначный выигрыш для глубокого RL, а такое случается нечасто.
Из-за этого мне сложнее объяснить непрофессионалам, почему мои проблемы крутые, сложные и интересные, потому что часто не имеют контекста или испытайте , чтобы понять, почему они трудны. Существует пробел в объяснении того, что, по мнению людей, может делать глубокий RL, и что он действительно может сделать. Я сейчас занимаюсь робототехникой. Рассмотрим компанию большинство людей думают о когда вы говорите о робототехнике: Boston Dynamics.
Не использует обучение с подкреплением. Я несколько раз беседовал, где люди думали, что он использует RL, но это не так. Если вы посмотрите исследовательские работы группы, вы найдете статьи, в которых упоминается переменные во времени LQR, решатели QP и выпуклая оптимизация. Другими словами, они в основном применяют классические методы робототехники. Оказывается эти классические техники могут работать очень хорошо, если вы их правильно применяете.
Обучение с подкреплением предполагает наличие функции вознаграждения.Обычно, это либо дается, либо настраивается вручную в автономном режиме и фиксируется в течение всего курса обучения. Я говорю «обычно», потому что есть исключения, например, имитация обучение или обратный RL, но большинство подходов RL рассматривают награду как оракул.
Важно, чтобы RL поступал правильно, ваша функция вознаграждения должна охватывать ровно то, что ты хочешь. И я имею в виду , ровно . У RL есть раздражающая тенденция переоснащаться вашей наградой, приводит к тому, чего вы не ожидали. Вот почему Atari — такой хороший тест.Не только легко ли собрать много образцов, цель каждой игры — набрать максимальное количество очков, так что вам никогда не придется беспокоиться об определении своей награды, и вы знаете всех остальное имеет ту же функцию вознаграждения.
Именно поэтому задачи MuJoCo популярны. Поскольку они выполняются в симуляции, у вас есть прекрасное знание всего состояния объекта, что делает дизайн функции вознаграждения намного проще.
В задаче Reacher вы управляете двухсегментной рукой, которая подключена к центральному точку, а цель — переместить конец руки в нужное место.Ниже это видео успешно изученной политики.
Так как все локации известны, награду можно определить как расстояние от конца руки до цели плюс небольшая стоимость контроля. В принципе, вы можете сделать это и в реальном мире, если у вас достаточно датчиков, чтобы достаточно точные позиции для вашей среды. Но в зависимости от того, что ты хочешь вашей системе, может быть трудно определить разумную награду.
Само по себе требование функции вознаграждения не будет большой проблемой, за исключением…
Превратить в функцию вознаграждения не так уж и сложно.Трудность наступает, когда вы пытаетесь разработать функцию вознаграждения, которая поощряет поведение, которое вы хотите пока еще можно учиться.
В среде HalfCheetah у вас есть двуногий робот, ограниченный вертикальная плоскость, то есть она может двигаться только вперед или назад.
Ваш браузер не поддерживает видеоэлемент.
Цель — научиться бегать. Награда — это скорость HalfCheetah.
Это награда в форме , что означает, что она дает увеличивающуюся награду в состояниях. которые ближе к конечной цели.Это контрастирует с редкими наградами, которые давать награду в состоянии цели и не давать никакой награды где-либо еще. Формованные награды часто намного легче освоить, потому что они дают положительные отзывы. даже если политика не нашла полного решения проблемы.
К сожалению, оформленные награды могут искажать обучение. Как было сказано ранее, это может привести к к поведению, которое не соответствует тому, что вы хотите. Хорошим примером является игра о гонках на лодках из сообщения в блоге OpenAI. Предполагаемая цель — закончить гонку.Вы можете себе представить, что скудная награда даст +1 награду за завершение до заданного времени и 0 награду в противном случае.
Предоставляемая награда дает очки за попадание в контрольные точки, а также дает награду за сбор бонусов, которые позволят вам быстрее закончить гонку. Оказывается, фарм бонусов дает больше очков, чем завершение гонки.
Честно говоря, я был немного раздражен, когда впервые появился этот пост в блоге. Этот не потому, что я думал, что это плохой момент! Это было потому, что я думал суть дела была ослепляюще очевидна.Конечно обучение с подкреплением делает странные вещи, когда награда указана неправильно! Это было похоже на сообщение сделал из данного примера неоправданно большую сделку.
Тогда я начал писать этот пост в блоге и понял, что самое интересное видео неправильно указанной награды было видео гонок на лодках. И с тех пор это видео использовался в нескольких презентациях, чтобы привлечь внимание к проблеме. Так хорошо, Я с неохотой признаю, что это был хороший пост в блоге.
алгоритмов RL попадают в континуум, где они предполагают более или менее знания об окружающей среде, в которой они находятся.Самая широкая категория, безмодельный РЛ, почти то же самое, что оптимизация черного ящика. Эти методы разрешены только для предположим, что они находятся в MDP. В противном случае им больше ничего не дается. Агент просто говорят, что это дает +1 к награде, а это нет, и ему нужно научиться остальное само по себе. Как и в случае с оптимизацией черного ящика, проблема в том, что все, что дает Награда +1 — это хорошо, даже если награда +1 не приходит по правильным причинам.
Классическим примером не-RL является случай, когда кто-то применил генетические алгоритмы к схемотехника, и получил схему, в которой неподключенный логический вентиль был необходим для окончательного дизайн.
Серые ячейки необходимы для правильного поведения, включая ячейку в верхнем левом углу, даже если он ни к чему не подключен. Из «Развитой схемы, присущей кремнию, связанной с физикой»
Более свежий пример см. Сообщение в блоге от Salesforce, 2017 г. Их цель — резюмирование текста. Их базовая модель обучается с обучением с учителем, а затем оценивается с помощью автоматизированный показатель под названием ROUGE. ROUGE недифференцируема, но RL может имеют дело с недифференцируемыми вознаграждениями, поэтому они попытались применить RL для оптимизации ROUGE напрямую.Это дает высокий ROUGE (ура!), Но на самом деле это не так. дайте хорошие резюме. Вот пример.
Баттону было отказано в его сотой гонке за McLaren после того, как ERS помешало ему выйти на старт. Это завершило для британца ужасные выходные. Баттон выбыл из квалификации. Финишировал впереди Нико Росберга в Бахрейне. У Льюиса Хэмилтона есть. В 11 гонках. . Гонка. Провести 2000 кругов. . В. . . А также.
Paulus et al, 2017
Итак, несмотря на то, что модель RL дает наивысшую оценку ROUGE…
вместо этого они использовали другую модель.
Вот еще один забавный пример. Это Попов и др., 2017, иногда называют «стопкой бумаги Lego». Авторы используют распределенную версию DDPG, чтобы изучить политику понимания. В Цель состоит в том, чтобы схватить красный блок и сложить его поверх синего блока.
Они заставили его работать, но столкнулись с аккуратным случаем отказа. За начальное подъемное движение награда дается в зависимости от того, насколько высоко красный блок является. Это определяется координатой z нижняя грань блока. Одним из способов отказа было то, что политика усвоила чтобы опрокинуть красный блок вместо того, чтобы поднять его.
Теперь ясно, что это не предполагаемое решение. Но Р.Л. все равно. С точки зрения обучения с подкреплением, он был вознагражден за то, что переворачивал блок, так что он будет продолжать переворачивать блоки.
Один из способов решить эту проблему — сделать вознаграждение разреженным, давая только положительные награда после того, как робот сложит блок. Иногда это срабатывает, потому что скудное вознаграждение можно выучить. Часто это не так, потому что отсутствие положительных подкрепление все усложняет.
Другой способ решить эту проблему — тщательно формировать вознаграждение, добавляя новые условия вознаграждения и коэффициенты настройки существующих до тех пор, пока поведение вы хотите научиться выпадать из алгоритма RL. возможно драться RL на этом фронте, но это очень неудовлетворительная борьба. Иногда это необходимо, но я никогда не чувствовал, что я чему-то научился, делая это.
Для справки, вот одна из функций вознаграждения из набора Lego. бумага.
Я не знаю, сколько времени было потрачено на разработку этой награды, но исходя из количество членов и количество различных коэффициентов, я собираюсь угадайте «много».
В разговорах с другими исследователями RL я слышал несколько анекдотов о новое поведение, которое они видели из-за неправильно определенных вознаграждений.
Сотрудник преподает агент для навигации по комнате. Эпизод завершается, если агент ходит за пределы. Он не добавил никаких штрафов, если серия заканчивает это способ. Последняя политика научилась быть суицидальной, потому что отрицательная награда была обильная, положительная награда была слишком трудной для достижения, и быстрая смерть закончилась в 0 награда была предпочтительнее долгой жизни с риском отрицательной награды.
Друг тренирует смоделированную руку робота, чтобы дотянуться до точки. над столом. Оказывается, точка была определена относительно таблицы , и стол ни к чему не был прикреплен. Политик научился очень сильно хлопать по столу, заставляя стол падать над, что тоже переместило целевую точку. Целевая точка так получилась упасть рядом с концом руки.
Исследователь рассказывает об использовании RL для обучения руки смоделированного робота возьмите молоток и забейте гвоздь.Изначально была определена награда. насколько сильно гвоздь вошел в отверстие. Вместо Взяв молоток, робот забил гвоздь собственными конечностями. Итак, они добавили термин вознаграждения, чтобы побудить брать в руки молот, и переучили политика. У них была политика забрать молоток … но затем он бросил молоток в гвоздь вместо того, чтобы использовать его.
По общему признанию, все это подержанные аккаунты, и я не видел видео с любое из этих действий. Однако мне все это кажется неправдоподобным.Р.Л. слишком много раз обжигал меня, чтобы поверить в обратное.
Я знаю людей, которые любят рассказывать истории об оптимизаторах скрепок. Я понял Я действительно так делаю. Но, честно говоря, мне надоело слышать эти истории, потому что они всегда придумывайте какие-то сверхчеловеческие смещенные ОИИ, чтобы создать такую историю. Нет никаких оснований предполагать так далеко, когда случаются современные примеры. все время.
Предыдущие примеры RL иногда называют «взломом вознаграждения». Мне, это подразумевает умное готовое решение, которое дает больше вознаграждения, чем предполагаемый ответ дизайнера функции вознаграждения.
Взлом награды — исключение. Гораздо более частым случаем является плохой локальный оптимум. это происходит из-за неправильного компромисса между разведкой и эксплуатацией.
Вот одно из моих любимых видео. Это реализация Нормализованная функция преимущества, обучение в среде HalfCheetah.
Ваш браузер не поддерживает видеоэлемент.
Со стороны это действительно действительно тупой. Но мы можем скажем, что это глупо, потому что мы можем видеть вид от третьего лица и заранее подготовленные знания, которые говорят нам, что бегать на ногах лучше.Р.Л. этого не знает! Он видит вектор состояния, отправляет векторы действий и знает, что получает положительную награду. Это оно.
Вот мое предположение о том, что произошло во время обучения.
- При случайном исследовании политика, обнаруженная, что падение вперед лучше, чем стоя на месте.
- Этого было достаточно, чтобы «прожечь» такое поведение, и теперь оно падает. последовательно.
- После падения политика узнала, что если она выполняет одноразовое приложение большой силы, он сделает сальто назад, что даст немного больше вознаграждения.
- Он изучил сальто достаточно, чтобы убедиться, что это хорошая идея, и теперь обратное перелистывание вписано в политику.
- Как только политика постоянно меняется, что проще для политика: научиться исправляться, а затем бежать «стандартным путем», или обучение или выясняя, как двигаться вперед, лежа на спине? я буду угадайте последнее.
Это очень забавно, но определенно не то, что я хотел от робота.
Вот еще один неудачный запуск, на этот раз в среде Ричера.
Ваш браузер не поддерживает видеоэлемент.
В этом прогоне исходные случайные веса имели тенденцию давать очень положительные или положительные значения. выходы крайне отрицательного действия. Это заставляет большинство действий выводить возможно максимальное или минимальное ускорение. Очень легко крутить супер быстро: просто приложите большие силы к каждому суставу. Когда робот начинает работать, становится сложно чтобы отклониться от этой политики значимым образом — чтобы отклониться, вы должны принять несколько шагов исследования, чтобы остановить безудержное вращение.Это конечно возможно, но в этом прогоне этого не произошло.
Это оба случая классической проблемы разведки и эксплуатации, которая преследовала Обучение с подкреплением с незапамятных времен. Ваши данные взяты из вашей текущей политики. Если ваша текущая политика тоже исследует вы получаете ненужные данные и ничего не узнаете. Слишком много эксплуатируйте, и вы выгораете поведение, которое не является оптимальным.
Есть несколько интуитивно приятных идей для решения этой проблемы. мотивация, исследование на основе любопытства, исследование на основе счета и т. д.Многие из этих подходов были впервые предложены в 1980-х годах или ранее, и некоторые из них были пересмотрены с помощью моделей глубокого обучения. Однако пока насколько я знаю, ни один из них не работает одинаково во всех средах. Иногда они помогают, иногда нет. Было бы неплохо, если бы была разведка трюк, который работал везде, но я скептически отношусь к серебряной пуле такого калибра будут обнаружены в ближайшее время. Не потому, что люди не пытаются, а потому что разведка-эксплуатация действительно, очень, очень, очень, очень сложно.Цитируя Википедию,
.Первоначально рассматриваемый союзными учеными во время Второй мировой войны, он оказался настолько трудноразрешимым, что, по словам Питера Уиттла, эту проблему предлагалось отбросить над Германией, чтобы немецкие ученые также могли тратить на нее свое время.
(Ссылка: Q-Learning for Bandit Problems, Duff 1995)
Я привык воображать глубокого RL как демона, который намеренно неверно истолковывают вознаграждение и активно ищут самых ленивых возможные локальные оптимумы.Это немного смешно, но я обнаружил, что на самом деле это продуктивное мышление.
Deep RL популярен, потому что это единственная сфера машинного обучения, где она социально допустимо тренироваться на тестовой выборке.
Источник
Плюс обучения с подкреплением в том, что если вы хотите Что ж, в окружающей среде вы можете безумно переобучаться. Обратной стороной является то, что если вы хотите обобщить на любую другую среду, вы, вероятно, собираетесь делаешь плохо, потому что переобучаешься как сумасшедший.
DQN может решить многие игры Atari, но делает это, фокусируя все учиться ради одной цели — стать действительно хорошим игроком в одной игре. Финальная модель не будет обобщать на другие игры, потому что он не был обучен таким образом. Вы можете настроить выученный DQN на новую игру Atari. (см. Прогрессивные нейронные сети (Rusu et al, 2016)), но нет никакой гарантии, что он будет перенесен, и люди обычно не ожидают, что это произойдет перевод. Это не тот бешеный успех, который люди видят от предварительно обученных функций ImageNet.
Чтобы предупредить очевидные комментарии: да, в принципе, тренировка на широком распределение сред должно устранить эти проблемы. В некоторых случаях вы получаете такую раздачу бесплатно. Пример это навигация, в которой вы можете случайным образом выбрать целевые местоположения и использовать универсальные функции ценности для обобщения. (См. Универсальные аппроксиматоры функции значений, Schaul et al, ICML 2015.) Я считаю эту работу очень многообещающей, и позже я приведу больше примеров из этой работы. Однако я не думаю, что возможности обобщения глубокого RL достаточно сильны, чтобы справиться с разнообразными набора задач пока нет.Восприятие стало намного лучше, но глубокий RL еще не есть момент «ImageNet для контроля». Вселенная OpenAI пыталась зажечь это, но из того, что я слышал, это было слишком сложно решить, поэтому не так много Выполнено.
Пока не наступит момент обобщения, мы будем придерживаться политики, может быть удивительно узким по своему охвату. В качестве примера (и как возможность подшутить над некоторыми из моих собственных работ): рассмотреть Может ли Deep RL решить игры Эрдоса-Селфриджа-Спенсера? (Рагху и др., 2017).Мы изучали игрушечную комбинаторную игру для двух игроков, в которой есть аналитическое решение в замкнутой форме. для оптимальной игры. В одном из наших первых экспериментов мы исправили поведение игрока 1, а затем обучили игрок 2 с RL. Поступая так, вы можете рассматривать действия игрока 1 как часть окружающей среды. Тренируя игрока 2 против оптимального игрока 1, мы показали RL может достичь высокой производительности. Но когда мы развернули то же самое политика против неоптимального игрока 1, ее производительность упала, потому что она не обобщал на неоптимальных оппонентов.
Lanctot et al, NIPS 2017 показал аналогичный результат. Здесь есть два агента играть в лазертаг. Агенты обучаются с мультиагентным подкреплением обучение. Чтобы проверить обобщение, они запускают обучение с 5 случайными семена. Вот видео агентов, которые были обучены против одного Другой.
Как видите, они учатся приближаться и стрелять друг в друга. Затем они взял игрока 1 из одного эксперимента и сопоставил его с игроком 2 из разных, эксперимент.Если усвоенные политики обобщают, мы должны увидеть подобное поведение.
Спойлер: нет.
Кажется, это текущая тема в мультиагентном RL. Когда агенты обучаются друг против друга происходит своего рода совместная эволюция. Агенты становятся действительно хорошими при избиении друг друга, но когда они выставляются против невидимого игрока, падает производительность. Я также хотел бы отметить, что Единственное различие между этими видео — случайное начальное число. Такое же обучение алгоритм, те же гиперпараметры.Расхождение в поведении чисто из-за случайности в начальных условиях.
При этом есть некоторые отличные результаты в конкурентной среде самостоятельной игры. которые, кажется, противоречат этому. У OpenAI есть хорошая запись в блоге о некоторых из их работ в этой области. Самостоятельная игра также является важной частью обоих AlphaGo и AlphaZero. Моя интуиция подсказывает, что если ваши агенты учатся в в одинаковом темпе, они могут постоянно бросать вызов друг другу и ускорять обучения, но если один из них учится намного быстрее, он эксплуатирует более слабого игрока слишком много и переборщить.Когда вы расслабляетесь от симметричной игры с самим собой до общей мультиагентные настройки, становится все труднее обеспечить обучение одновременно скорость.
Почти каждый алгоритм машинного обучения имеет гиперпараметры, которые влияют на поведение системы обучения. Часто их выбирают вручную или путем случайного поиска.
Обучение с учителем стабильно. Фиксированный набор данных, наземные цели. если ты немного измените гиперпараметры, ваша производительность не сильно изменится. Не все гиперпараметры работают хорошо, но со всеми эмпирическими уловками, обнаруженными с годами, многие гиперпарамы будут проявлять признаки жизни во время тренировки.Эти признаки жизни очень важно, потому что они говорят вам, что вы на правильном пути, вы делать что-то разумное, и на это стоит потратить больше времени.
В настоящее время глубокий RL совсем нестабилен, и это очень раздражает для исследования.
Когда я начал работать в Google Brain, одним из первых то, что я сделал, это реализовал алгоритм из функции нормализованного преимущества бумага. Я подумал, что это займет у меня около 2-3 недель. У меня было несколько вещей для меня: некоторое знакомство с Theano (которое перенесено на TensorFlow хорошо), некоторый глубокий опыт RL, и первым автором статьи NAF был стажировался в Brain, так что я мог засыпать его вопросами.
На воспроизведение результатов у меня ушло 6 недель благодаря нескольким программам. ошибки. Вопрос в том, почему на поиск этих ошибок ушло так много времени?
Чтобы ответить на этот вопрос, рассмотрим простейшую задачу непрерывного управления в OpenAI Gym: задача маятника. В этой задаче есть маятник, закрепленный в точке, где на маятник действует сила тяжести. Состояние ввода 3-х мерный. Пространство действия является одномерным, величина крутящего момента, который необходимо приложить. Цель состоит в том, чтобы уравновесить маятник идеально вертикально.
Это крошечная проблема, и ее еще больше облегчает грамотно оформленная награда. Награда определяется углом маятника. Действия, приводящие маятник ближе к вертикали не только дают награду, они дают , увеличивая награды. Ландшафт вознаграждения в основном вогнутый.
Ниже приведено видео политики, которая в основном работает . Хотя политика не балансировать прямо вверх, он выдает точный крутящий момент, необходимый для противодействия сила тяжести.
Ваш браузер не поддерживает видеоэлемент.
Вот график производительности после того, как я исправил все ошибки. Каждая строка — это кривая вознаграждения от одного из 10 независимых прогонов. Те же гиперпараметры, единственные разница — это случайное семя.
Семь из этих прогонов сработали. Три из этих пробежек не дали результатов. A 30% частота отказов считается рабочей. Вот еще один сюжет из какой-то опубликованной работы, «Вариационная информация, максимизирующая исследования» (Houthooft et al, NIPS 2016). Окружающая среда — HalfCheetah. Награда изменена, чтобы быть более разреженной, но детали не так уж и важны.Ось Y — награда за эпизод, ось X — количество временных шагов, а используемый алгоритм — TRPO.
Темная линия — это медианная эффективность по 10 случайным семенам, а заштрихованная регион находится с 25-го по 75-й процентиль. Не поймите меня неправильно, этот сюжет хороший Аргумент в пользу VIME. Но с другой стороны, линия 25-го процентиля действительно близко к нулю награды. Это означает, что около 25% запусков терпят неудачу, просто из-за случайного семени.
Послушайте, в контролируемом обучении тоже есть расхождения, но они редко бывают настолько плохими.Если бы мой код контролируемого обучения не превышал случайную вероятность в 30% случаев, я бы иметь сверхвысокую уверенность в том, что произошла ошибка при загрузке данных или обучении. Если мой код обучения с подкреплением работает не лучше, чем случайный, я понятия не имею, это ошибка, если у меня плохие гиперпараметры или мне просто не повезло.
Это изображение из статьи «Почему машинное обучение такое« сложное »?». Основной тезис заключается в том, что машинное обучение добавляет больше измерений вашему пространству. случаев отказов, что в геометрической прогрессии увеличивает количество возможных неудач.Deep RL добавляет новое измерение: случайный шанс. И единственный способ обратиться к случайный шанс состоит в том, чтобы провести достаточно экспериментов над проблемой, чтобы заглушить шум.
Когда ваш алгоритм обучения является неэффективным и нестабильным как выборка, он сильно замедляет вашу продуктивность исследования. Может потребоваться всего 1 миллион шаги. Но когда вы умножаете это на 5 случайных семян, а затем умножаете на настройка гиперпарам, вам потребуется огромное количество вычислений для проверки гипотез эффективно.
Если вам от этого станет легче, я занимаюсь этим некоторое время, и у меня ушло около 6 недель, чтобы получить с нуля реализацию градиентов политики для работы в 50% случаев над кучей проблем RL. У меня также есть кластер GPU, доступный мне, и несколько друзей, с которыми я обедаю каждый день, которые были в этом районе в течение последних нескольких лет.
Кроме того, то, что мы знаем о хорошем дизайне CNN из области контролируемого обучения, похоже, неприменимо к области обучения с подкреплением, потому что вы в основном сталкиваетесь с узкими местами из-за назначения кредитов / битрейта надзора, а не из-за отсутствия мощного представления.Ваши ResNets, батчнормы или очень глубокие сети здесь не работают.
[Обучение с учителем] хочет работать. Даже если вы что-то напортачите, вы получите взамен что-то неслучайное. Р.Л. нужно заставить работать. Если вы что-то напортачите или не настроите что-то достаточно хорошо, очень вероятно, что вы получите политику, которая даже хуже, чем случайная. И даже если все будет хорошо настроено, в 30% случаев политика будет неверной только потому, что.
Короче говоря, ваша неудача в большей степени связана со сложностью глубокого RL и гораздо меньше из-за сложности «проектирования нейронных сетей».
Комментарий Hacker News от Андрея Карпати, когда он был в OpenAI
Неустойчивость к случайному посеву похожа на канарейку в угольной шахте. Если чистая случайность достаточно, чтобы привести к такой большой разнице между прогонами, представьте, сколько фактических разница в коде может иметь значение.
К счастью, нам не нужно вообразить, потому что это было проверено статья «Глубокое обучение с подкреплением, которое имеет значение» (Хендерсон и др., AAAI 2018). Среди его выводов:
- Умножение вознаграждения на константу может привести к значительным различиям в производительности.
- Пяти случайных начальных чисел (общая метрика отчетности) может быть недостаточно, чтобы спорить значительный результат, так как при тщательном выборе можно получить неперекрывающиеся доверительные интервалы.
- Различные реализации одного и того же алгоритма имеют разную производительность на та же задача, даже если используются одни и те же гиперпараметры.
Моя теория заключается в том, что RL очень чувствителен как к вашей инициализации, так и к динамика вашего тренировочного процесса, потому что ваши данные всегда собираются онлайн и единственное наблюдение, которое вы получаете, — это один скаляр для вознаграждения.Политика, которая случайно наткнется на хорошие обучающие примеры, сильно самозагрузится быстрее, чем политика, которая этого не делает. Политика, не позволяющая найти хорошее обучение примеры со временем рухнут и не узнают вообще ничего, так как это станет более уверенно, что любое отклонение, которое он попытается, потерпит неудачу.
Глубокое обучение с подкреплением, безусловно, сделало несколько очень интересных вещей. DQN — это старые новости сейчас, но было абсолютно орехов на то время. Единственная модель смогла учиться прямо из необработанных пикселей, без настройки для каждой игры индивидуально.AlphaGo и AlphaZero продолжают оставаться очень впечатляющими достижениями.
Однако, помимо этих успехов, трудно найти случаи, когда глубокий RL создала практическую ценность в реальном мире.
Я попытался представить себе реальное, производственное использование глубокого RL, и это было на удивление сложно. Я ожидал найти что-то в рекомендательных системах, но я считаю, что в них по-прежнему преобладает совместная фильтрация и контекстные бандиты.
В итоге лучшее, что я смог найти, — это два проекта Google: сокращение объема данных центральное энергопотребление, и недавно объявленный проект AutoML Vision.Джек Кларк из OpenAI написал в Твиттере аналогичный запрос и нашел аналогичный вывод. (Твит написан в прошлом году, до анонса AutoML.)
Я знаю, что Audi что-то делает с глубоким RL, так как они продемонстрировали беспилотное вождение. Радиоуправляемая машина в НИПС и сообщила, что в ней используется глубокий RL. Я знаю, что есть аккуратная работа оптимизация размещения устройств для больших графов Tensorflow (Mirhoseini et al, ICML 2017). У Salesforce есть своя модель резюмирования текста, которая работает, если вы массируете RL достаточно внимательно. Финансовые компании, конечно, экспериментируют с RL, пока мы говорим, но пока окончательных доказательств нет.(Конечно, у финансовых компаний есть причины уклоняться о том, как они играют на рынке, так что, возможно, доказательства никогда не собираются быть сильным.) Facebook проделал некоторую аккуратную работу с глубоким RL для чат-ботов и беседа. Каждая интернет-компания когда-либо думала о добавлении RL в их модель показа рекламы, но если кто-то и делал это, они об этом умалчивают.
На мой взгляд, глубокий RL все еще является предметом исследования, который не является надежным. достаточно для широкого использования, или его можно использовать, и люди, которые его получили на работу не афишируют.Я думаю, что первое более вероятно.
Если вы обратились ко мне с проблемой классификации изображений, я бы указал вам предварительно обученные модели ImageNet, и они, вероятно, преуспеют. Мы в мире, где люди, стоящие за Silicon Valley могут создать настоящее приложение Not Hotdog как шутку. Мне трудно увидеть то же самое с глубоким RL.
Априори сложно сказать. Проблема с попыткой решить все с RL заключается в том, что вы пытаетесь решить несколько очень разных сред с таким же подходом.Вполне естественно, что это не срабатывает все время.
При этом мы можем сделать выводы из текущего списка глубоких успехи в обучении с подкреплением. Это проекты, где глубокий RL либо учится качественно впечатляющему поведению, или он учится чему-то лучше, чем сопоставимая предыдущая работа. (Правда, это это очень субъективный критерий.)
Вот мой список.
(Небольшое отступление: машинное обучение недавно превзошло профессиональных игроков в безлимитных играх). возглавляет Техасский холдем.Это было сделано как Libratus (Brown et al, IJCAI 2017) и DeepStack (Моравчик и др., 2017). Я разговаривал с несколькими людьми, которые считали, что это было сделано с помощью глубокого RL. Они оба очень крутые, но они не используют глубокий RL. Они используют минимизацию ложных сожалений и умное итеративное решение подигры.)
Из этого списка мы можем определить общие свойства, облегчающие обучение. Ни одно из перечисленных ниже свойств не требует , требуется для обучения, но удовлетворяет больше из них окончательно лучше.
Легко получить почти неограниченное количество опыта. Должно быть понятно, почему это помогает. Чем больше у вас данных, тем легче обучение проблема есть. Это относится к Atari, Go, Chess, Shogi и симулированная среда для паркур-бота. Скорее всего, это относится и к проекту энергоцентра, потому что в предыдущей работе (Gao, 2014), было показано, что нейронные сети могут прогнозировать энергоэффективность с высокой точность. Это именно та имитационная модель, которая нужна вам для обучения Система RL.
Это может относиться к работе Dota 2 и SSBM, но это зависит от пропускной способности. насколько быстро можно запускать игры и сколько машин было доступно для запустить их.
Задача упрощена до более легкой формы. Одна из распространенных ошибок Я видел в глубоком RL — это слишком большие мечты. Обучение с подкреплением может сделать что-нибудь! Это не значит, что нужно делать все сразу.
Бот OpenAI Dota 2 играл только в раннюю игру, играл только Shadow Fiend против Shadow Злодей в сеттинге 1 на 1 использовал жестко запрограммированные сборки предметов и, предположительно, называется Dota 2 API чтобы избежать необходимости решать восприятие.Бот SSBM показал сверхчеловеческие характеристики, но это было только в играх 1 на 1, только с Captain Falcon, только в Battlefield, в бесконечном матче времени.
Это не копирование ни одного из ботов. Зачем работать над сложной проблемой, если ты не даже знаете, что более простой вариант разрешим? В Общая тенденция всех исследований — продемонстрировать наименьшее доказательство концепции сначала и обобщить позже. OpenAI расширяет свою работу по Dota 2 и продолжается работа по распространению бота SSBM на других персонажей.
Есть способ ввести самостоятельную игру в обучение. Это компонент AlphaGo, AlphaZero, бота Dota 2 Shadow Fiend и бота SSBM Falcon. я Следует отметить, что под самостоятельной игрой я подразумеваю именно ту настройку, в которой соревновательные, и оба игрока могут управляться одним и тем же агентом. До сих пор, этот параметр кажется наиболее стабильным и эффективным.
Есть чистый способ определить обучаемую, неиграбельную награду. Игры для двух игроков имейте это: +1 за победу, -1 за поражение.В исходной статье по поиску нейронной архитектуры от Zoph et al, ICLR 2017 было следующее: точность проверки обученная модель. Каждый раз, когда вы вводите формирование вознаграждения, вы вводите шанс для изучения неоптимальной политики, которая оптимизирует неправильную цель.
Если вас интересует дополнительная информация о том, что является хорошей наградой, Хороший поисковый запрос — «правильное правило оценки». См. Это сообщение в блоге Терренса Тао, где можно найти доступный пример.
Что касается обучаемости, у меня нет совета, кроме как попробовать, чтобы убедиться, что работает.
Если награда должна быть оформлена, она должна быть по крайней мере богатой. В Dota 2 награда может быть получена за ластхиты (срабатывает после каждого убийства монстра. любым игроком) и здоровье (срабатывает после каждой атаки или умения, которое попадает в цель.) Эти сигналы вознаграждения приходи быстро и часто. Для бота SSBM награда может быть дана за нанесенный урон и взят, что дает сигнал для каждой успешной атаки. Короче задержка между действием и последствиями, тем быстрее петля обратной связи становится закрыто, и тем легче обучению с подкреплением найти путь к высокой награде.
Мы можем объединить несколько принципов, чтобы проанализировать успех Neural Архитектурный поиск. Согласно первоначальной версии ICLR 2017, после 12800 примеров глубокий RL смог разработать современную нейронную сетевые архитектуры. По общему признанию, каждый пример требовал обучения нейронной сети. к сходимости, но это по-прежнему очень эффективно с точки зрения выборки.
Как упоминалось выше, награда — это точность проверки. Это очень богатый сигнал вознаграждения — если решение по дизайну нейронной сети только возрастет. точность от 70% до 71%, RL все равно поймет это.Кроме того, есть доказательства того, что гиперпараметры в глубоком обучении близки к линейно независимый. (Это было эмпирически показано в гиперпараметре Оптимизация: спектральный подход (Hazan et al, 2017) — мое резюме вот если интересно.) NAS не совсем настраивает гиперпараметры, но я думаю, что это разумно что проектные решения нейронной сети будут действовать аналогичным образом. Это хорошо новости для обучения, потому что корреляция между решением и производительностью сильны. Наконец, не только вознаграждение богато, но и то, что нас волнует. о том, когда мы обучаем моделей.
Сочетание всех этих пунктов помогает мне понять, почему «всего» 12800 обученных сетей, чтобы изучить лучшую, по сравнению с миллионами примеров необходимо в других средах. Некоторые части проблемы все усиливаются. Благосклонность Р.Л.
В целом, такие сильные истории успеха все еще являются исключением, а не правилом. Чтобы обучение с подкреплением было правдоподобным, многое должно происходить правильно. решение, и даже в этом случае, это не бесплатная поездка, чтобы реализовать это решение.
Вкратце: глубокий RL в настоящее время не является технологией plug-and-play.
Есть старая поговорка — каждый исследователь учится ненавидеть свою область изучение. Хитрость в том, что исследователи будут продолжать, несмотря на это, потому что они мне слишком нравятся проблемы.
Примерно так я отношусь к глубокому обучению с подкреплением. Несмотря на мою оговорки, я думаю, что люди должны бросать RL в разные проблемы, в том числе те, где, вероятно, не должно работать. Как еще мы должен сделать RL лучше?
Я не вижу причин, по которым глубокий RL не смог бы работать, учитывая больше времени.Несколько очень интересные вещи произойдут, когда глубокий RL станет достаточно надежным для более широкого использовать. Вопрос в том как он туда попадет.
Ниже я перечислил некоторые варианты будущего, которые считаю правдоподобными. Для фьючерсов на основании дальнейших исследований я привел ссылки на соответствующие статьи в этих области исследований.
Локальные оптимумы достаточно хороши: Было бы очень высокомерно утверждать, что люди глобально оптимально ни при чем. Думаю, мы достаточно хороши, чтобы получить до стадии цивилизации по сравнению с любыми другими видами.В том же духе Решение RL не обязательно должно достигать глобального оптимума, если его локальные оптимумы лучше, чем у человека.
Аппаратное обеспечение решает все: Я знаю некоторых людей, которые считают, что Важная вещь, которую можно сделать для ИИ, — это просто увеличить масштаб оборудования. Лично, Я скептически отношусь к тому, что оборудование все исправит, но, безусловно, быть важным. Чем быстрее вы можете запускать вещи, тем меньше вы заботитесь о пробах неэффективность, и тем легче перебором пройти мимо исследования проблемы.
Добавьте дополнительный обучающий сигнал: Редкие награды трудно выучить, потому что вы получаете очень мало информации о том, что вам поможет. Возможно, мы либо галлюцинируем положительные награды (Hindsight Experience Replay, Andrychowicz et al, NIPS 2017), определение вспомогательных задач (UNREAL, Jaderberg et al, NIPS 2016), или начните с самостоятельного обучения, чтобы построить хорошую модель мира. Добавление больше вишни к торту, так сказать.
Обучение на основе моделей раскрывает эффективность выборки: Вот как я описываю модельный РЛ: «Все хотят это делать, немногие знают, как это сделать.» В принципе, хорошая модель решает кучу проблем. Как видно в AlphaGo, имея модель вообще значительно упрощает поиск хорошего решения. Хорошие мировые модели хорошо перенесут на новые задачи, и развертывание модели мира позволит вам представить новый опыт. От того, что я Как видно, подходы, основанные на моделях, также используют меньше выборок.
Проблема в том, что выучить хорошие модели сложно. У меня такое впечатление, что низкоразмерные модели состояния иногда работают, и изображение модели обычно слишком жесткие.Но, если это станет проще, кое-что интересное могло случиться.
Dyna (Саттон, 1991) и Dyna-2 (Silver et al., ICML 2008) являются классические работы в этой области. Для работ, сочетающих обучение на основе моделей с глубокими сетями, я бы порекомендовал несколько недавних работ из лабораторий робототехники Беркли: Динамика нейронной сети для глубокой RL на основе моделей с точной настройкой без модели (Nagabandi et al, 2017, Самоконтролируемое визуальное планирование с временными пропусками связей (Ebert et al, CoRL 2017), Объединение обновлений на основе моделей и без них для обучения с подкреплением, ориентированного на траектории (Chebotar et al, ICML 2017).Глубокие пространственные автоэнкодеры для зрительно-моторного обучения (Finn et al, ICRA 2016), и управляемый поиск политики (Levine et al, JMLR 2016).
Используйте обучение с подкреплением в качестве шага точной настройки: Первый AlphaGo Работа началась с контролируемого обучения, а затем на его основе была проведена тонкая настройка RL. Это хороший рецепт, поскольку он позволяет использовать более быстрый, но менее мощный метод. для ускорения начального обучения. Он работал в других контекстах — см. Sequence Tutor (Jaques et al, ICML 2017). Вы можете рассматривать это как начало процесса RL с разумным приоритетом, а не как случайный, где проблема изучения априорной возлагается на некоторые другой подход.
Функции вознаграждения можно изучить: Обещание ML состоит в том, что мы можем использовать данные, чтобы изучать то, что лучше, чем задумано человеком. Если дизайн функции вознаграждения так сложно, почему бы не применить это, чтобы лучше изучить функции вознаграждения? Имитация обучение и обучение с обратным подкреплением — это богатые области, в которых показанные функции вознаграждения могут быть неявно определяется человеческими демонстрациями или человеческими оценками.
Известные статьи по инверсному RL и имитационному обучению см. Алгоритмы обучения с обратным подкреплением (Нг и Рассел, ICML 2000), Практическое обучение через обучение с обратным подкреплением (Abbeel and Ng, ICML 2004), и DAgger (Росс, Гордон и Багнелл, AISTATS 2011).
Информацию о недавней работе по масштабированию этих идей для глубокого обучения см. В разделе Guided Cost Learning (Finn et al, ICML 2016), Time-Constrastive Networks (Sermanet et al, 2017), и изучение человеческих предпочтений (Christiano et al, NIPS 2017). (В частности, в статье о человеческих предпочтениях что награда, полученная на основе человеческих оценок, на самом деле лучше подходит для обучения чем исходная жестко запрограммированная награда, что является отличным практическим результатом.)
Для более долгосрочной работы без глубокого обучения мне понравился Обратный дизайн вознаграждения (Hadfield-Menell et al, NIPS 2017) и обучение задач роботов на основе физического взаимодействия с человеком (Bajcsy et al, CoRL 2017).
Трансферное обучение спасает положение: Трансферное обучение обещает вы можете использовать знания из предыдущих задач, чтобы ускорить изучение новых. Я думаю, что это абсолютно будущее, когда обучение задач станет достаточно надежным, чтобы решить несколько разрозненных задач. Трудно перенести обучение, если вы не можете учиться вообще, и учитывая задачу A и задачу B, может быть очень трудно предсказать переходит ли A в B. По моему опыту, это либо супер очевидно, либо супер непонятно, и даже в сверхъестественных случаях нетривиально заставить работать.
Универсальные аппроксиматоры функции значений (Schaul et al, ICML 2015), Дистральный (Whye Teh et al, NIPS 2017), и «Преодоление катастрофического забвения» (Kirkpatrick et al, PNAS 2017) — недавние работы в этом направлении. Для более старых работ рассмотрите возможность чтения Horde (Sutton et al, AAMAS 2011).
Робототехника в частности, был достигнут значительный прогресс в переносе сим-карты в реальную (трансферное обучение между смоделированной версией задачи и реальной задачей). См. Раздел «Рандомизация домена» (Tobin et al, IROS 2017), Робот от Sim-to-Real Обучение с помощью прогрессивных сетей (Rusu et al, CoRL 2017), а также GraspGAN (Bousmalis et al, 2017).(Отказ от ответственности: я работал над GraspGAN.)
Хорошие предварительные оценки могут значительно сократить время обучения: Это тесно связано с несколько предыдущих пунктов. С одной точки зрения, трансферное обучение — это использование прошлый опыт, чтобы построить хороший априор для изучения других задач. Алгоритмы RL предназначены для применения к любому марковскому процессу принятия решений, который где возникает боль общности. Если мы согласимся с тем, что наши решения будут хорошо работать только на небольшом участке среды, мы должны иметь возможность использовать общую структуру для решения этих среды эффективным способом.
One Point Питер Аббель в своих выступлениях любит упоминать, что глубокому RL нужно решать только те задачи, которые мы ожидаем, что это понадобится в реальном мире. Я согласен, в этом есть большой смысл. Должно существовать реальный априор, который позволяет нам быстро изучать новые реальные задачи за счет медленного обучения над нереалистичными задачами, но это вполне приемлемый компромисс.
Сложность в том, что такой реальный приор будет очень сложно спроектировать. Однако я думаю, что это вполне возможно.Лично я восхищен недавней работой в области метаобучения, поскольку она обеспечивает управляемый данными способ получения разумных априорных значений. Например, если бы я хотел использовать RL для навигации по складу, я бы неплохо интересно использовать метаобучение, чтобы заранее изучить хорошую навигацию, а затем точную настройку приора для конкретного склада робот будет развернут в. Это очень похоже на будущее, и вопрос в том, может ли метаобучение попадет или нет.
Краткое изложение недавних практических занятий можно найти в это сообщение от BAIR (Berkeley AI Research).
Более сложные условия парадоксальным образом могут быть проще: Один из главных уроков из статьи о паркуре DeepMind заключается в том, что если вы сделаете свою задачу очень сложной добавив несколько вариантов задач, вы действительно можете сделать обучение проще, потому что политика не может соответствовать ни одному параметру без потери производительность на всех остальных настройках. Мы видели подобное в статьи о рандомизации предметной области и даже обратно в ImageNet: модели, обученные на ImageNet будет обобщать лучше, чем обученные на CIFAR-100.Как я сказал выше, возможно, мы просто «ImageNet для контроля», а не делаем RL значительно более общий.
С точки зрения окружающей среды вариантов много. OpenAI Gym легко имеет наибольшую привлекательность, но есть также среда обучения аркад, Робошкола, DeepMind Lab, DeepMind Control Suite и ELF.
Наконец, хотя результаты исследования неудовлетворительны В перспективе эмпирические вопросы глубокого RL могут не иметь значения для практических целей. Как гипотетический пример, предположим, что финансовая компания использует глубокий RL.Они тренируют торговый агент на основе прошлых данных с фондового рынка США, используя 3 случайных числа. При живом A / B-тестировании один дает на 2% меньше дохода, один выполняет то же самое, а один дает на 2% больше дохода. В этой гипотетической воспроизводимости не имеет значения — вы разворачиваете модель с увеличением дохода на 2% и радуетесь. Точно так же не имеет значения, что торговый агент может работать только хорошо. в Соединенных Штатах — если он плохо распространяется на мировой рынок, просто не размещайте его там. Между тем, что-то делать, большой разрыв экстраординарный и делает этот выдающийся успех воспроизводимым, и, возможно, это В первую очередь стоит остановиться на бывшем.
Во многих отношениях меня раздражает текущее состояние глубокого RL. Тем не менее, это привлекло одни из самых сильных исследователей. интерес, который я когда-либо видел. Мои чувства лучше всего выражаются мышлением, Эндрю Нг упомянул в своей книге «Орехи и болты применения глубокого обучения». разговоры — много краткосрочного пессимизма, уравновешенного еще более долгосрочным оптимизмом. Deep RL сейчас немного запутан, но я все еще верю в то, где это могло быть.
При этом в следующий раз, когда меня спросят, может ли обучение с подкреплением решить их проблема, я все равно скажу им, что нет, не может.Но я также скажу их, чтобы спросить меня снова через несколько лет.